



📢 转载信息
原文作者:Babs Khalidson, Christelle Xu, Manuel Gomez, Nuno Castro, Vushesh Babu Adhikari, Zainab Afolabi, and Bryan Woolgar-O'Neil, Jamie Cockrill, Adrian Cunliffe
本文由 Bryan Woolgar-O’Neil、Jamie Cockrill 和 Adrian Cunliffe(均来自 Harmonic Security)协助撰写
组织在支持第三方生成式AI工具的同时,保护敏感数据正面临着日益严峻的挑战。Harmonic Security是一家网络安全公司,他们开发了一个AI治理和控制层,可以在员工使用AI时实时发现敏感数据,使安全团队能够在业务加速发展的同时保护个人身份信息(PII)、源代码和薪资信息等安全。
下面的截图展示了Harmonic Security的软件工具,其中突出了不同类型的数据泄露检测,包括员工PII、员工财务信息和源代码。
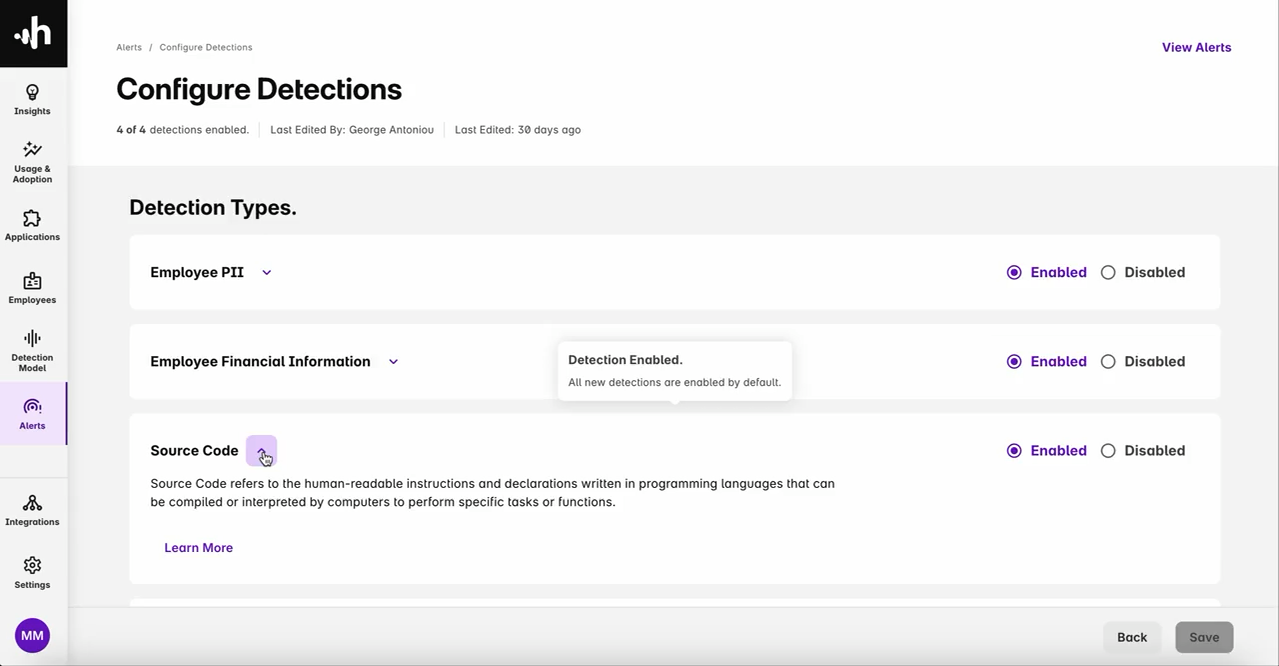
Harmonic Security的解决方案现已在AWS Marketplace上架,使组织能够通过无缝的AWS集成来部署企业级的数据泄露防护。该平台提供了对GenAI使用情况的提示级别可见性、在风险点提供实时指导,以及检测高风险AI应用——所有这些都由本文所述的优化模型提供支持。
他们系统的初始版本虽然有效,但1-2秒的检测延迟为进一步增强功能和改善整体用户体验留下了提升空间。为此,Harmonic Security与AWS生成式AI创新中心合作,确定了四个关键目标来优化其系统:
- 将第95百分位数的检测延迟降低到500毫秒以下
- 在监控的数据类型上保持检测准确性
- 继续支持欧盟数据驻留合规性
- 为生产负载启用可扩展架构
本文将介绍Harmonic Security如何使用Amazon SageMaker AI、Amazon Bedrock和Amazon Nova Pro来微调一个ModernBERT模型,从而实现低延迟、准确且可扩展的数据泄露检测。
解决方案概述
Harmonic Security初始的数据泄露检测系统依赖于一个80亿(8B)参数的模型,该模型能够有效地识别敏感数据,但会产生1-2秒的延迟,这已接近影响用户体验的阈值。为了在保持准确性的同时实现亚500毫秒的延迟,我们使用微调后的ModernBERT模型开发了两种分类方法。
首先,我们优先考虑了一个二元分类模型来检测并购(M&A)内容,这是帮助防止敏感数据泄露的关键类别。我们最初专注于二元分类,因为它是最简单的方法,可以无缝集成到他们当前并行调用多个二元分类模型的系统中。其次,作为一种扩展,我们探索了多标签分类模型,以在单次通过中检测多种敏感数据类型(如账单信息、财务预测和雇佣记录),旨在减少运行多个并行二元分类器的计算开销以提高效率。尽管多标签方法在未来可扩展性方面显示出潜力,但Harmonic Security决定在初始版本中保留二元分类模型。该解决方案使用了以下关键服务:
- Amazon SageMaker AI – 用于模型的微调和部署
- Amazon Bedrock – 用于访问行业领先的大语言模型(LLMs)
- Amazon Nova Pro – 一个功能强大、平衡了准确性、速度和成本的多模态模型
下图说明了用于低延迟推理和可扩展性的解决方案架构。
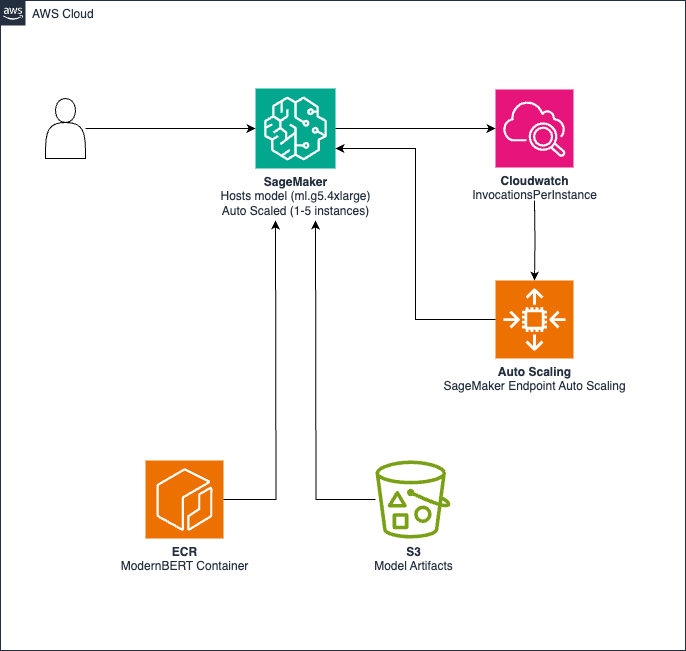
该架构由以下组件构成:
- 模型工件存储在Amazon Simple Storage Service (Amazon S3) 中
- 包含推理代码的自定义容器托管在Amazon Elastic Container Registry (Amazon ECR) 中
- SageMaker 端点使用
ml.g5.4xlarge实例进行 GPU 加速推理 - Amazon CloudWatch 监控调用,并根据每分钟830个请求(RPM)的阈值触发自动扩展以调整实例数量(1–5)。
该解决方案支持以下功能:
- 亚500毫秒的推理延迟
- 支持欧盟AWS区域部署
- 根据需求在1到5个实例之间自动扩展
- 在低使用期间进行成本优化
合成数据生成
高质量的敏感信息(如并购文件和财务数据)训练数据非常稀缺。我们使用Meta Llama 3.3 70B Instruct和Amazon Nova Pro生成合成数据,扩展了Harmonic现有的数据集,该数据集包括以下类别的示例:并购、账单信息、财务预测、雇佣记录、销售渠道和投资组合。下图提供了合成数据生成过程的高层概述。
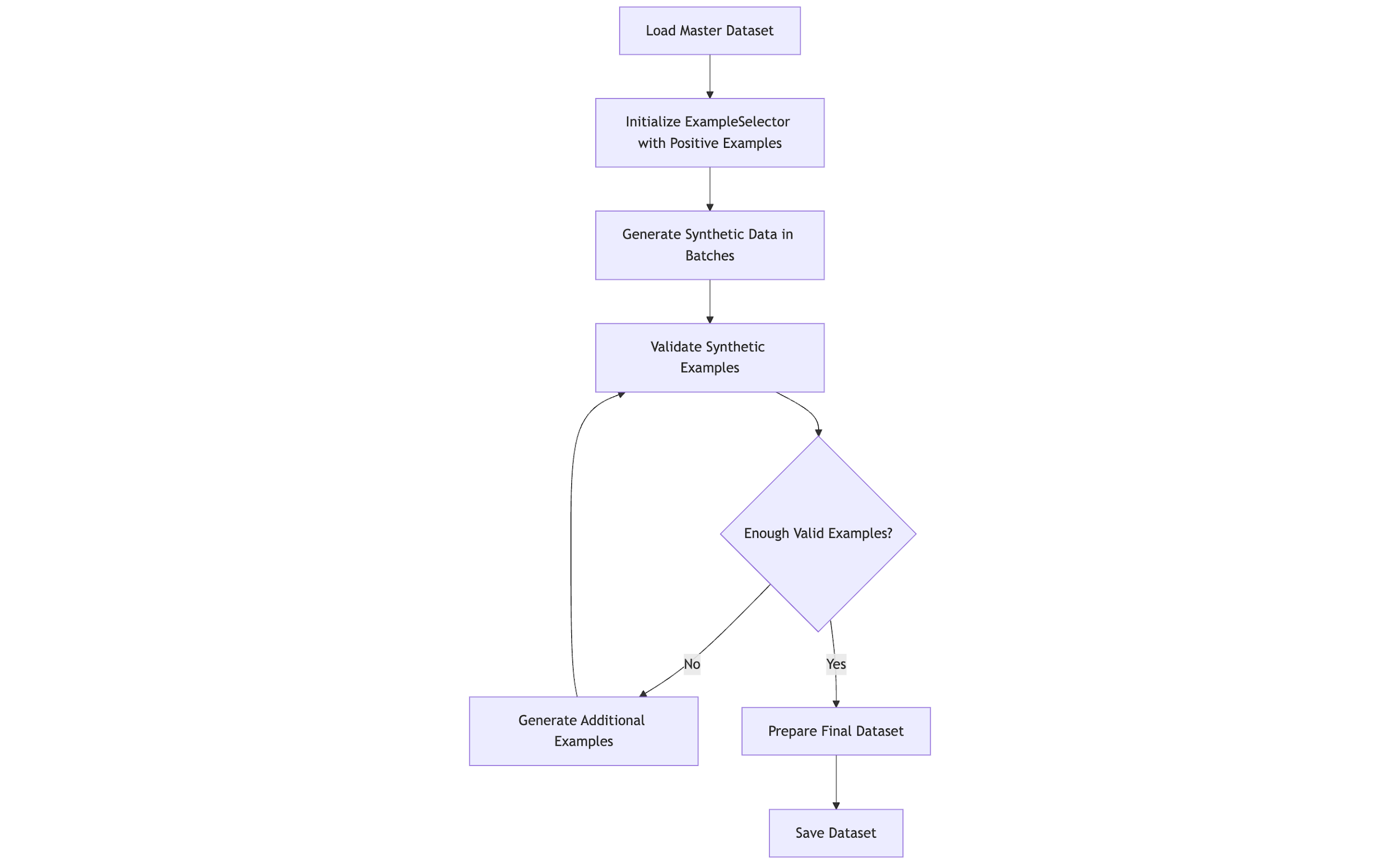
数据生成框架
合成数据生成框架由一系列步骤组成,包括:
- 智能示例选择 – 对句子嵌入进行K-均值聚类,支持多样化的示例选择
- 自适应提示 – 提示中融入了领域知识,并根据类别调整温度(0.7–0.85)和top-p采样
- “差点”增强(Near-miss augmentation) – 生成与阳性案例相似的阴性示例,以提高精确度
- 验证 – 使用Amazon Nova Pro和Meta Llama 3的LLM-即-裁判方法验证示例的相关性和质量
二元分类
对于二元并购分类任务,我们生成了三种不同类型的示例:
- 阳性示例 – 这些示例包含明确的并购信息,同时保持了逼真的文档结构和特定于金融的语言模式。它们包括“合并”、“收购”、“交易条款”和“协同效应估算”等关键指标。
- 阴性示例 – 我们创建了与领域相关的、但故意避开了并购特征的内容,同时在上下文上适合商业沟通。
- “差点”示例 – 这些示例类似于阳性示例,但仅处于分类边界之外。例如,讨论战略合作或合资企业但未构成实际并购活动的文档。
生成过程精确地维持了这些示例类型之间的比例,特别强调了“差点”示例以满足精确度的要求。
多标签分类
对于跨越四个敏感信息类别的更复杂的多标签分类任务,我们开发了一种复杂的生成策略:
- 单标签示例 – 我们生成了仅包含与一个类别相关信息的示例,以建立清晰的类别特定特征
- 多标签示例 – 我们创建了跨越多个类别的示例,并控制了分布,涵盖了各种组合(2–4个标签)
- 类别特定要求 – 对于每个类别,我们定义了强制性元素,以维持明确而非隐含的关联:
- 财务预测 – 前瞻性收入和增长数据
- 投资组合 – 关于持股和业绩指标的详细信息
- 账单和付款信息 – 发票和供应商账户
- 销售渠道 – 机会和预期收入
我们的多标签生成优先考虑类别之间现实的共现模式,同时确保各个类别及其组合得到充分代表。结果是,合成数据使训练示例增加了10倍(二元)和15倍(多标签)。它还改善了类别平衡,因为我们确保以更平衡的标签分布来生成数据。
模型微调
我们使用SageMaker对ModernBERT模型进行了微调,以实现低延迟和高准确性。与Meta Llama 3.2 3B和Google Gemma 2 2B等仅解码器模型相比,ModernBERT的紧凑尺寸(1.49亿和3.95亿参数)带来了更快的延迟,同时仍然提供更高的准确性。因此,我们选择了ModernBERT而不是微调其他替代模型。此外,ModernBERT是少数支持长达8,192个Token上下文长度的BERT类模型之一,这是我们项目的关键要求。
二元分类模型
我们的第一个微调模型使用了ModernBERT-base,我们专注于M&A内容的二元分类。我们系统地处理了这项任务:
- 数据准备 – 我们用合成生成的数据丰富了M&A数据集
- 框架选择 – 我们在PyTorch环境中使用了Hugging Face transformers库和Trainer API,运行在SageMaker上
- 训练过程 – 我们的过程包括:
- 分层抽样以在训练和评估集中保持标签分布
- 使用最长3,000个Token的序列长度进行专业分词,以匹配客户在生产中的情况
- 二元交叉熵损失优化
- 基于F1分数进行提前停止以防止过拟合。
结果是一个微调后的模型,它能以比8B参数模型更高的F1分数区分M&A内容和非敏感信息。
多标签分类模型
对于更复杂的多标签分类任务(在单个文本片段中同时检测多种敏感数据类型),我们微调了一个ModernBERT-large模型,以在单次通过中识别各种敏感数据类型,如账单信息、雇佣记录和财务预测。这要求:
- 多热标签编码(Multi-hot label encoding) – 我们将类别转换为向量格式以进行同步预测。
- Focal Loss实现 – 我们没有使用标准的交叉熵损失,而是实现了一个自定义的
FocalLossTrainer类。与静态加权损失函数不同,Focal Loss在训练期间会自适应地降低简单示例的权重。这有助于模型集中精力处理具有挑战性的案例,显著提高对不频繁或更难检测类别的性能。 - 专业化配置 – 我们为每个类别的概率添加了可配置的类别阈值(例如0.1到0.8),以确定标签分配,因为我们观察到不同决策边界上的性能有所不同。
这种方法使我们的系统能够在一次推理中识别多种敏感数据类型。
超参数优化
为了找到模型的最佳配置,我们使用Optuna来优化关键参数。Optuna是一个开源的超参数优化(HPO)框架,它通过运行许多实验(称为“试次”)来帮助找到给定机器学习(ML)模型的最佳超参数。它使用一种称为树状结构的Parzen估计器(TPE)的贝叶斯算法,根据过去的试验结果选择有希望的超参数组合。
搜索空间探索了关键超参数的众多组合,如下表所示。
| 超参数 | 范围 |
| 学习率 | 5e-6–5e-5 |
| 权重衰减 | 0.01–0.5 |
| 预热比率 | 0.0–0.2 |
| Dropout率 | 0.1–0.5 |
| 批次大小 | 16, 24, 32 |
| 梯度累积步数 | 1, 4 |
| Focal Loss Gamma(仅多标签) | 1.0–3.0 |
| 类别阈值(仅多标签) | 0.1–0.8 |
为了优化计算资源,我们实现了剪枝逻辑,以提前停止性能不佳的试次,从而可以丢弃效率较低的配置。如以下Optuna HPO历史图所示,试次42具有针对二元分类的最佳参数和最高的F1分数,而试次32是多标签的最佳选择。
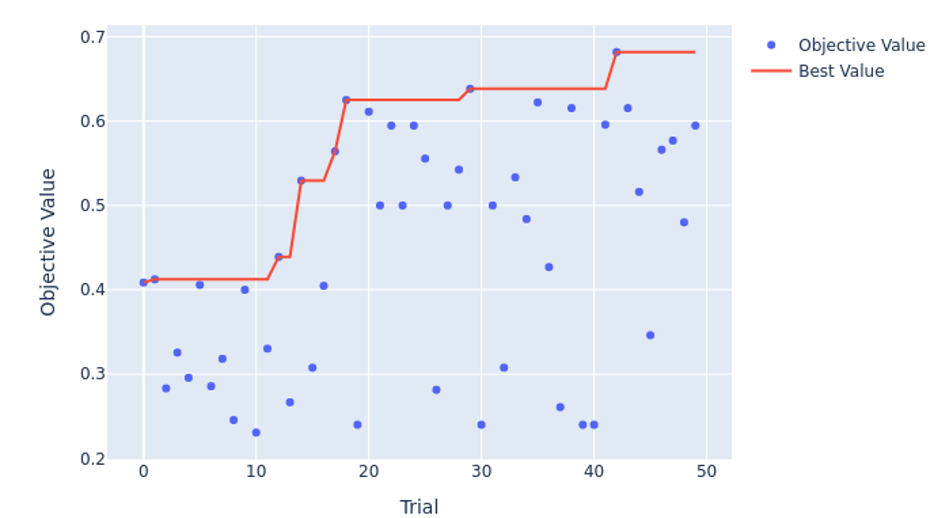
此外,我们的分析表明,Dropout和学习率是最重要的超参数,分别占二元分类模型F1分数方差的48%和21%。这解释了我们为什么在之前的运行中观察到模型快速过拟合,并强调了正则化的重要性。
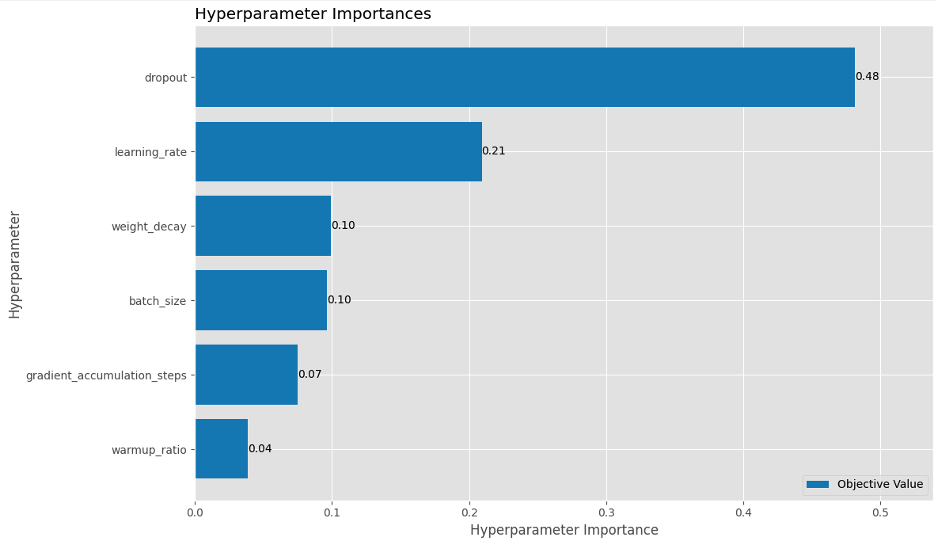
在优化实验之后,我们发现:
- 我们能够为每项任务确定最佳超参数
- 模型在训练过程中收敛得更快
- 最终性能指标显示出比我们手动测试的配置可衡量的改进
这使我们的模型能够通过自动化的方式运行超参数调优来高效地实现高F1分数,这对于生产部署至关重要。
负载测试和自动扩展策略
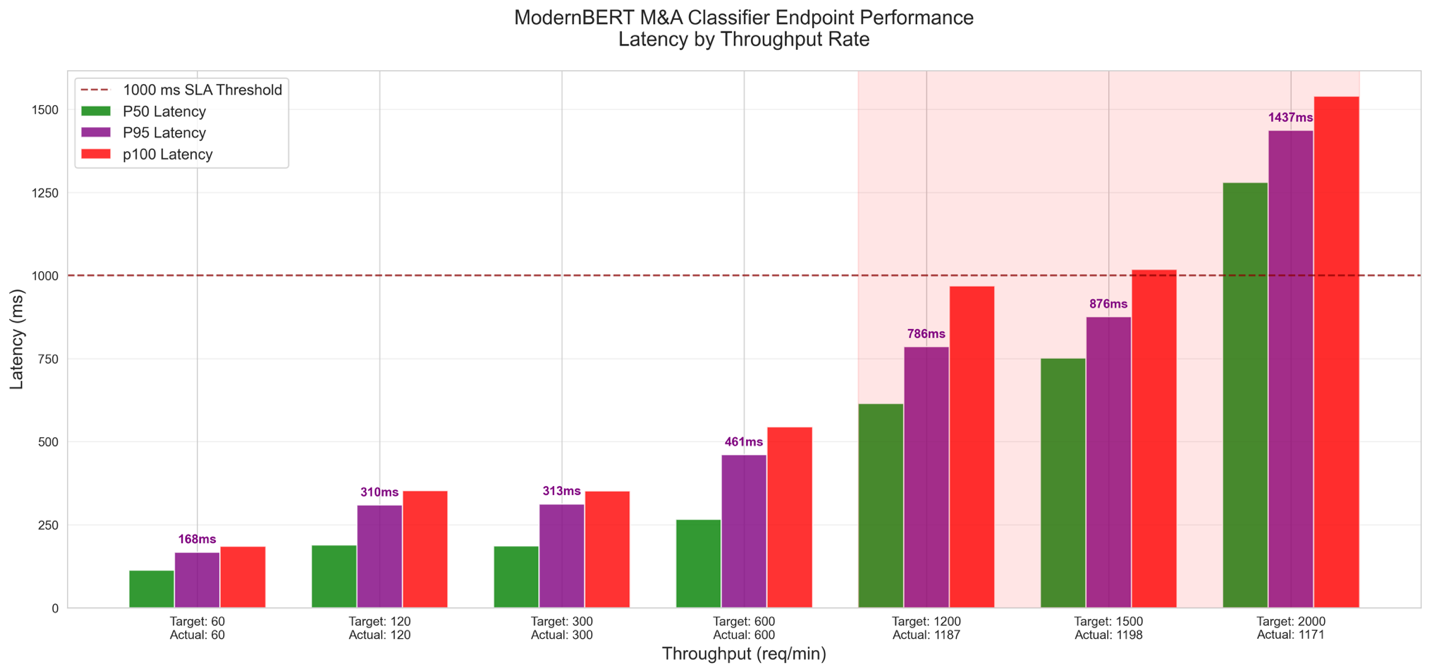
在微调优化的模型并将其部署到SageMaker实时端点后,我们进行了负载测试,以验证其在压力下的性能和自动扩展能力,以满足Harmonic Security在延迟、吞吐量和弹性方面的需求。负载测试的目标是:
- 验证延迟SLA,在变化负载下平均低于500毫秒,P95约为1秒
- 确定使用
ml.g5.4xlarge实例在延迟SLA内能达到的最大RPM吞吐量 - 为自动扩展策略设计提供信息
我们的方法包括:
- 流量模拟 – Locust模拟并发用户流量,文本长度不同(50–9,999个字符)
- 负载模式 – 我们采用了阶梯式增加测试(60–2,000 RPM,每个60秒),以识别瓶颈并对压力极限进行压力测试
如下面的负载测试图所示,我们发现延迟在1秒以内的最大吞吐量为1,185 RPM,因此我们决定将自动扩展阈值设置为其70%,即830 RPM。
根据负载测试期间观察到的性能,我们使用Application Auto Scaling为SageMaker端点配置了目标跟踪自动扩展策略。下图说明了这个策略的工作流程。

定义的关键参数是:
- 指标 –
SageMakerVariantInvocationsPerInstance(每实例每分钟830次调用) - 最小/最大实例 – 1–5
- 冷却时间 – 扩展(Scale-out)300秒,缩减(Scale-in)600秒
这种目标跟踪策略根据流量调整实例,保持了性能和成本效益。下表总结了我们的发现。
| 模型 | 每分钟请求数 |
|---|---|
| 8B模型 | 800 |
| 使用自动扩展的ModernBERT(5个实例) | 1,185-5925 |
| 额外容量(ModernBERT 对比 8B 模型) | 48%-640% |
结果
本节展示了微调和优化工作对Harmonic Security数据泄露检测系统的显著影响,重点在于实现显著的延迟降低。首先介绍了绝对延迟改进,突显了成功达到亚500毫秒目标,然后概述了性能增强。以下小节详细介绍了二元M&A分类和跨多种敏感数据类型的多标签分类的具体结果。
二元分类
我们评估了微调后的ModernBERT-base模型用于二元M&A分类与解决方案概述中介绍的基线8B模型。最引人注目的成就是延迟的革命性降低,解决了最初1-2秒的延迟,这种延迟可能会破坏用户体验。向亚500毫秒延迟的飞跃在下表中有所详细,标志着系统响应能力的关键增强。
| 模型 | median_ms | p95_ms | p99_ms | p100_ms |
|---|---|---|---|---|
| Modernbert-base-v2 | 46.03 | 81.19 | 102.37 | 183.11 |
| 8B模型 | 189.15 | 259.99 | 286.63 | 346.36 |
| 差异 | -75.66% | -68.77% | -64.28% | -47.13% |
在延迟突破的基础上,以下性能指标反映了准确率和F1分数百分比的提高。
| 模型 | 准确率提升 | F1提升 |
| ModernBERT-base-v2 | +1.56% | +2.26% |
| 8B模型 | – | – |
这些结果表明,ModernBERT-base-v2实现了突破性的延迟降低,并辅以适度的准确率和F1分数提升(分别为1.56%和2.26%),这与Harmonic Security在不影响用户体验的情况下增强数据泄露检测的目标相一致。
多标签分类
我们评估了微调后的ModernBERT-large模型用于多标签分类与基线8B模型的性能,延迟降低是该方法的核心。最显著的进步是所有评估类别的延迟大幅度下降,实现了亚500毫秒的响应能力,解决了先前1-2秒的瓶颈。下表中的延迟结果突显了这一关键改进。
| 数据集 | 模型 | median_ms | p95_ms | p99_ms |
| 账单和支付 | 8B模型 | 198 | 238 | 321 |
| ModernBERT-large | 158 | 199 | 246 | |
| 差异 | -20.13% | -16.62% | -23.60% | |
| 销售渠道 | 8B模型 | 194 | 265 | 341 |
| ModernBERT-large | 162 | 243 | 293 | |
| 差异 | -16.63% | -8.31% | -13.97% | |
| 财务预测 | 8B模型 | 384 | 510 | 556 |
| ModernBERT-large | 160 | 275 | 310 | |
| 差异 | -58.24% | -46.04% | -44.19% | |
| 投资组合 | 8B模型 | 397 | 498 | 703 |
| ModernBERT-large | 160 | 259 | 292 | |
| 差异 | -59.69% | -47.86% | -58.46% |
这种方法还带来了第二个关键优势:通过将多个分类整合到一个单次通过中,减少了计算并行化的需求。然而,多标签模型在所有类别中保持一致的准确性方面遇到了挑战。尽管财务预测和投资组合等类别的准确性显示出有希望的提高,但诸如账单和支付以及销售渠道等其他类别的准确性却出现了显著下降。这表明,尽管在延迟和并行性方面具有优势,但该方法需要在跨数据类型保持可靠准确性方面进行进一步的开发。
结论
在本文中,我们探讨了Harmonic Security如何与AWS生成式AI创新中心合作,优化其数据泄露检测系统并取得变革性成果:
关键性能提升:
- 延迟降低:从1-2秒降至500毫秒以下(中位数降低76%)
- 吞吐量增加:通过自动扩展实现48%-640%的额外容量
- 准确率提升:二元分类提高+1.56%,并在类别间保持了精度
通过使用SageMaker、Amazon Bedrock和Amazon Nova Pro,Harmonic Security微调了ModernBERT模型,这些模型在生产中实现了亚500毫秒的推理,满足了严格的性能目标,同时支持欧盟合规性并建立了可扩展的架构。
这次合作展示了定制化的AI解决方案如何在不影响生产力的情况下应对关键的网络安全挑战。Harmonic Security的解决方案现已在AWS Marketplace上架,使组织能够安全地采用AI工具,同时实时保护敏感数据。展望未来,这些高速模型有潜力为更多AI工作流程添加额外的控制。
要了解更多信息,请考虑以下后续步骤:
- 试用Harmonic Security – 直接从AWS Marketplace部署解决方案,以保护贵组织的使用情况
- 探索AWS服务 – 深入了解SageMaker、Amazon Bedrock和Amazon Nova Pro,以构建高级... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区