



📢 转载信息
原文作者:Samit Kumbhani, David Mbonu, and Jhorlin De Armas
PDI Technologies 是便利零售和石油批发行业的全球领导者。他们通过安全地连接数据和操作,帮助全球企业提高效率和盈利能力。凭借 40 年的经验,PDI Technologies 在业务的各个方面为客户提供协助,从理解消费者行为到简化供应链中的技术生态系统。
企业面临着一个重大挑战,即如何使其知识库可供 AI 系统访问、可搜索且可用。PDI Technologies 的内部团队正努力解决信息分散在各种系统中(包括网站、Confluence 页面、SharePoint 站点和各种其他数据源)的问题。为解决此问题,PDI Technologies 构建了 PDI Intelligence Query (PDIQ),这是一个 AI 助手,通过易于使用的聊天界面为员工提供公司知识的访问权限。该解决方案由一个定制的 检索增强生成 (RAG) 系统提供支持,该系统基于 Amazon Web Services (AWS) 并使用了无服务器技术。构建 PDIQ 需要解决以下关键挑战:
- 自动从具有不同身份验证要求的多样化源中提取内容
- 需要灵活性来选择、应用和互换最适合多样化处理需求的 大型语言模型 (LLM)
- 处理和索引内容以实现语义搜索和上下文检索
- 创建一个知识基础,以支持准确、相关的 AI 响应
- 通过计划的抓取持续刷新信息
- 在 AI 交互中支持企业特定的上下文
在本文中,我们将介绍 PDIQ 的流程和架构,重点介绍实施细节以及它为 PDI 带来的业务成果。
解决方案架构
在本节中,我们将探讨 PDIQ 全面的端到端设计。我们将研究从初始处理到存储再到用户搜索功能的数据摄取管道,以及在整个平台交互过程中保护关键用户角色的零信任安全框架。该架构由以下元素组成:
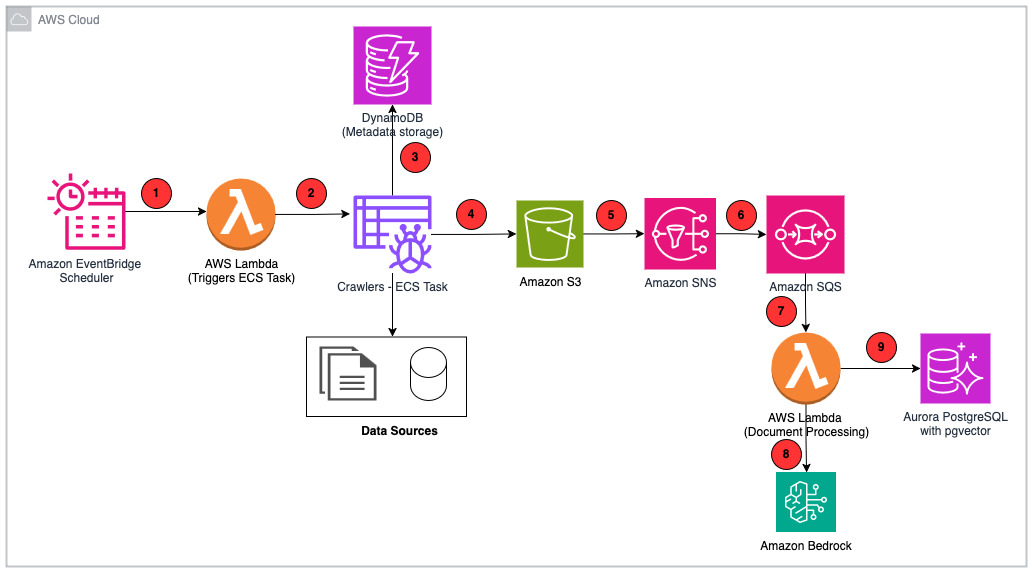
- 调度器 (Scheduler) – Amazon EventBridge 维护并执行爬虫调度器。
- 爬虫 (Crawlers) – AWS Lambda 调用作为任务由 Amazon Elastic Container Service (Amazon ECS) 执行的爬虫。
- Amazon DynamoDB – 持久化爬虫配置和其他元数据,例如 Amazon Simple Storage Service (Amazon S3) 图像位置和标题。
- Amazon S3 – 所有源文档都存储在 Amazon S3 中。Amazon S3 事件会触发下游流程,以处理每个被创建或删除的对象。
- Amazon Simple Notification Service (Amazon SNS) – 接收来自 Amazon S3 事件的通知。
- Amazon Simple Queue Service (Amazon SQS) – 订阅 Amazon SNS 以在队列中保存传入请求。
- AWS Lambda – 处理分块、总结和生成向量嵌入的业务逻辑。
- Amazon Bedrock – 提供对 PDIQ 使用的基础模型 (FM) 的 API 访问:
- Amazon Nova Lite 用于生成图像标题
- Amazon Nova Micro 用于生成文档摘要
- Amazon Titan Text Embeddings V2 用于生成向量嵌入
- Amazon Nova Pro 用于生成对用户查询的响应
- Amazon Aurora PostgreSQL 兼容版 – 存储向量嵌入。
下图是解决方案架构。
接下来,我们回顾 PDIQ 如何针对两个关键角色实施具有角色访问控制的零信任安全模型:
- 管理员 (Administrators) 通过与企业单点登录 (SSO) 集成的 Amazon Cognito 用户组配置知识库和爬虫。爬虫凭据使用 AWS Key Management Service (AWS KMS) 进行静态加密,并且只能在隔离的执行环境中访问。
- 最终用户 (End users) 根据在应用程序层验证的组权限访问知识库。用户可以属于多个组(例如人力资源或合规性),并切换上下文以查询适合其角色的数据集。
流程
在本节中,我们将回顾端到端流程。我们将其分解为几个部分,以便深入研究每个步骤并解释其功能。
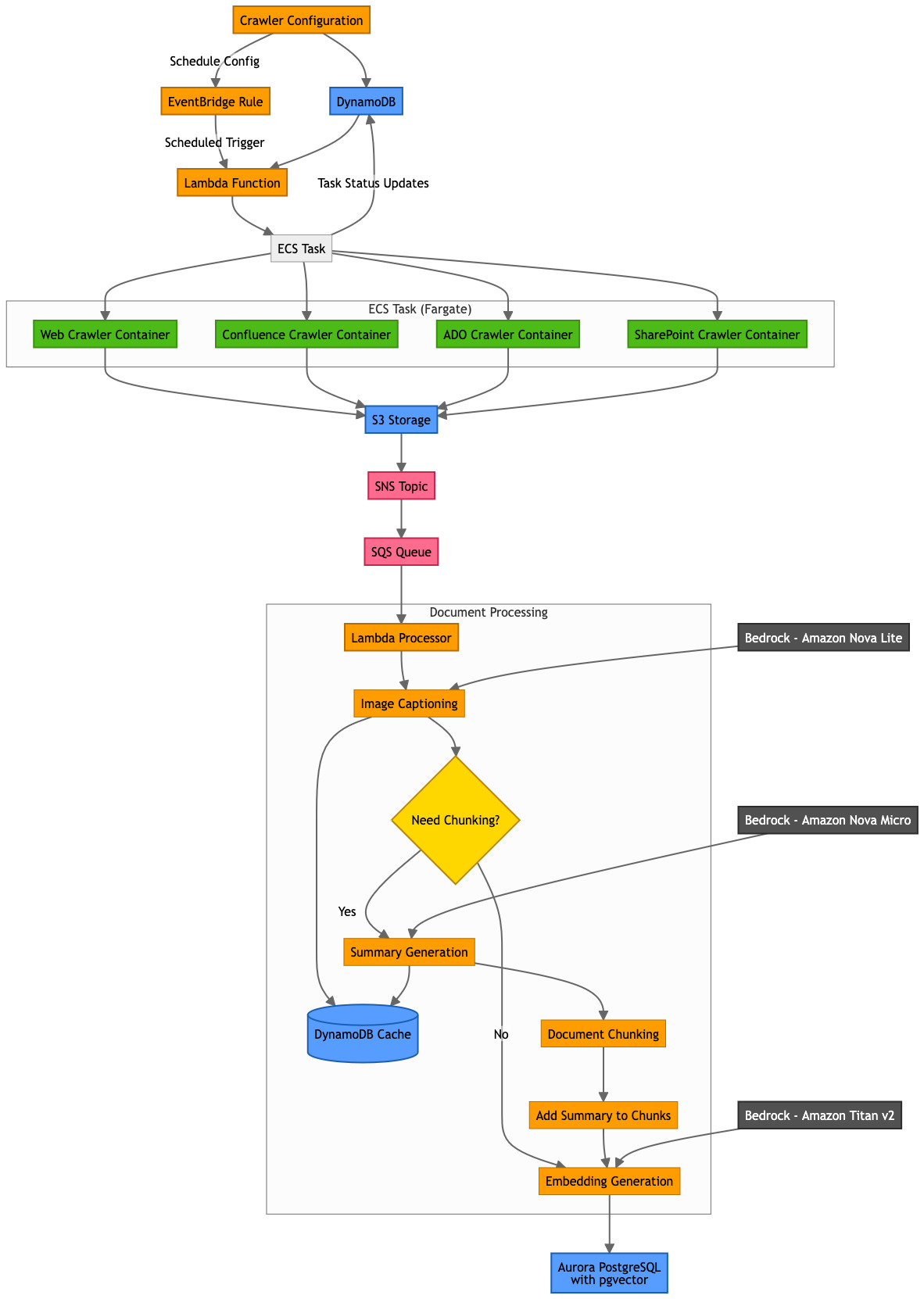
爬虫
爬虫由管理员配置,用于从 PDI 所依赖的各种源收集数据。爬虫将数据“水合”(填充)到知识库中,以便最终用户可以检索此信息。PDIQ 目前支持以下爬虫配置:
- Web 爬虫 (Web crawler) – 通过使用 Puppeteer 进行无头浏览器自动化,爬虫将 HTML 网页转换为 Markdown 格式,使用了 turndown。通过遵循网站上嵌入的链接,爬虫可以捕获页面的完整上下文和关系。此外,爬虫会下载 PDF 和图像等资产,同时保留原始引用,并为用户提供速率限制等配置选项。
- Confluence 爬虫 (Confluence crawler) – 此爬虫使用带有身份验证访问的 Confluence REST API 来提取页面内容、附件和嵌入的图像。它会保留页面层次结构和关系,处理诸如信息框、注释等特殊的 Confluence 元素,以及更多内容。
- Azure DevOps 爬虫 (Azure DevOps crawler) – PDI 使用 Azure DevOps 来管理其代码库、跟踪提交并在集中式存储库中维护项目文档。PDIQ 使用带有 OAuth 或个人访问令牌 (PAT) 身份验证的 Azure DevOps REST API 来提取此信息。Azure DevOps 爬虫保留项目层次结构、冲刺关系和待办事项列表结构,同时还会映射工作项关系(例如父/子或链接项),从而提供数据集的完整视图。
- SharePoint 爬虫 (SharePoint crawler) – 它使用带有 OAuth 身份验证的 Microsoft Graph API 来提取文档库、列表、页面和文件内容。爬虫将 MS Office 文档(Word、Excel、PowerPoint)处理成可搜索文本,并维护文档版本历史记录和权限元数据。
通过构建单独的爬虫配置,PDIQ 提供了易于扩展的平台,可以按需配置其他爬虫。它还为管理员用户提供了配置其各自爬虫设置(例如频率、深度或速率限制)的灵活性。
下图显示了用于配置知识库的 PDIQ 用户界面。
下图显示了用于配置爬虫(例如 Confluence)的 PDI 用户界面。

下图显示了 PDIQ 用户界面中用于调度爬虫的界面。

处理图像
抓取的数据以带有适当元数据标签的方式存储在 Amazon S3 中。如果源是 HTML 格式,任务会将内容转换为 Markdown (.md) 文件。对于这些 Markdown 文件,会执行额外的优化步骤,将文档中的图像替换为 Amazon S3 引用位置。此方法的关键优势包括:
- PDI 可以使用 S3 对象键来唯一引用每个图像,从而优化同步过程以检测源数据的变化
- 可以通过用标题替换图像并避免存储重复图像来优化存储
- 它提供了使图像内容可搜索并与文档中文本内容相关联的能力
- 在向用户查询返回响应时,无缝注入原始图像
以下是一个 Markdown 文件的示例,其中图像已替换为 S3 文件位置:
文档处理
这是流程中最关键的步骤。此步骤的关键目标是生成向量嵌入,以便可以根据用户查询进行相似性匹配和有效检索。该过程遵循几个步骤,从图像标题生成开始,然后是文档分块、摘要生成和嵌入生成。要为图像生成标题,PDIQ 会扫描 Markdown 文件以定位图像标签 <image>。对于这些图像中的每一个,PDIQ 会扫描并生成一个解释图像内容的标题。此标题会注入回 Markdown 文件中,紧邻 <image> 标签,从而丰富文档内容。这种方法提高了上下文可搜索性。PDIQ 通过将从图像中提取的见解直接嵌入到原始 Markdown 文件中来增强内容发现。这种方法确保图像内容成为可搜索文本的一部分,从而在搜索和分析期间实现更丰富、更准确的上下文检索。该方法还有助于节省成本。为避免对完全相同的图像进行不必要的 LLM 推理调用,PDIQ 将图像元数据(文件位置和生成的标题)存储在 Amazon DynamoDB 中。此步骤支持高效重用先前生成的标题,无需向 LLM 进行重复的标题生成调用。
以下是图像标题提示的示例:
You are a professional image captioning assistant. Your task is to provide clear, factual, and objective descriptions of images. Focus on describing visible elements, objects, and scenes in a neutral and appropriate manner.以下是包含图像标签、LLM 生成的标题以及相应 S3 文件位置的 Markdown 文件片段:
![image-20230818-114454: The image displays a security tip notification on a computer screen. The notification is titled "Security tip" and advises the user to use generated passwords to keep their accounts safe. The suggested password, "2m5oFX#g&tLRMhN3," is shown in a green box. Below the suggested password, there is a section labeled "Very Strong," indicating the strength of the password. The password length is set to 16 characters, and it includes lowercase letters, uppercase letters, numbers, and symbols. There is also a "Dismiss" button to close the notification. Below the password section, there is a link to "See password history." The bottom of the image shows navigation icons for "Vault," "Generator," "Alerts," and "Account." The "Generator" icon is highlighted in red.]
(https:// amzn-s3-demo-bucket.s3.amazonaws.com/kb/ABC/file/attachments/12133171243_image-20230818-114454.png)现在 Markdown 文件已注入图像标题,下一步是将原始文档分解成适合嵌入模型上下文窗口的块。PDIQ 使用 Amazon Titan Text Embeddings V2 模型生成向量,并将它们存储在 Aurora PostgreSQL 兼容的 Serverless 数据库中。根据内部准确性测试和 AWS 的分块最佳实践,PDIQ 如下执行分块:
- 70% 的令牌用于内容
- 块之间有 10% 的重叠
- 20% 用于摘要令牌
使用上一步的文档分块逻辑,文档被转换为向量嵌入。该过程包括:
- 计算块参数 – 根据 70% 的计算确定文档所需的块大小和总数。
- 生成文档摘要 – 使用 Amazon Nova Lite 根据 20% 的令牌分配为整个文档创建摘要。此摘要在所有块中重复使用,以提供一致的上下文。
- 分块并前置摘要 – 将文档分成重叠的块(10%),并在顶部前置摘要。
- 生成嵌入 – 使用 Amazon Titan Text Embeddings V2 为每个块(摘要 + 内容)生成向量嵌入,然后将其存储在向量存储中。
通过设计一种定制化的方法,在所有块的顶部生成摘要部分,PDIQ 确保当某个块基于相似性搜索匹配时,LLM 可以访问文档的整个摘要,而不仅仅是匹配的那个块。这种方法丰富了最终用户体验,使准确性批准率从 60% 提高到 79%。
以下是可用于每个块的摘要文本示例:
### Summary: PLC User Creation Process and Password Reset
**Document Overview:**
This document provides instructions for creating new users and resetting passwords **Key Instructions:** {Shortened for Blog illustration} This summary captures the essential steps, requirements, and entities involved in the PLC user creation and password reset process using Jenkins.
---块 1 顶部有一个摘要,然后是源的详细信息:
{Summary Text from above}
This summary captures the essential steps, requirements, and entities involved in the PLC user creation and password reset process using Jenkins. title: 2. PLC User Creation Process and Password Reset 块 2 顶部有一个摘要,然后是源详细信息的延续:
{Summary Text from above}
This summary captures the essential steps, requirements, and entities involved in the PLC user creation and password reset process using Jenkins.
---
Maintains a menu with options such as PDIQ 扫描每个文档块并生成向量嵌入。这些数据存储在 Aurora PostgreSQL 数据库中,其中包含关键属性,包括唯一的知识库 ID、相应的嵌入属性、原始文本(摘要 + 块 + 图像标题)以及包含用于扩展的元数据字段的 JSON 二进制对象。为了保持知识库同步,PDI 实施了以下步骤:
- 添加 (Add) – 这些是应摄取的新源对象。PDIQ 实施了前面描述的文档处理流程。
- 更新 (Update) – 如果 PDIQ 确定存在相同的对象,它会比较源中的哈希键值与 JSON 对象中的哈希值。
- 删除 (Delete) – 如果 PDIQ 确定特定的源文档不再存在,它会触发 S3 存储桶上的删除操作 (
s3:ObjectRemoved:*),这将导致清理作业,删除 Aurora 表中与键值对应的记录。
PDI 使用 Amazon Nova Pro 检索最相关的文档,并通过遵循以下关键步骤生成响应:
- 使用相似性搜索,检索最相关的文档块,其中包括摘要、块数据、图像标题和图像链接。
- 对于匹配的块,检索整个文档。
- LLM 然后将图像链接替换为来自 Amazon S3 的实际图像。
- LLM 根据检索到的数据和预先配置的系统提示生成响应。
以下是系统提示的片段:
Support assistant specializing in PDI's Logistics(PLC) platform, helping staff research and resolve support cases in Salesforce. You will assist with finding solutions, summarizing case information, and recommending appropriate next steps for resolution. Professional, clear, technical when needed while maintaining accessible language. Resolution Process:
Response Format template:
Handle Confidential Information:成果和后续步骤
通过在 AWS 上构建此定制的 RAG 解决方案,PDI 实现了以下好处:
- 灵活的配置选项允许以消费者偏好的频率进行数据摄取。
- 可扩展的设计支持未来通过易于配置的爬虫从其他源系统进行摄取。
- 支持使用多种身份验证方法配置爬虫,包括用户名和密码、密钥值对和 API 密钥。
- 可定制的元数据字段支持高级过滤并提高查询性能。
- 动态令牌管理帮助 PDI 智能地平衡内容和摘要之间的令牌,增强用户响应。
- 将多样化的源数据格式整合到统一的布局中,以实现简化的存储和检索。
PDIQ 带来了关键的业务成果,包括:
- 提高效率和解决率 – 该工具使 PDI 支持团队能够显著更快地解决客户查询,通常通过自动化常规问题并提供即时、准确的响应来实现。这减少了客户等待案例解决的时间,使座席的工作效率更高。
- 高客户满意度和忠诚度 – PDIQ 通过提供基于实时文档和公司知识的准确、相关和个性化的答案,提高了客户满意度评分 (CSAT)、净推荐值 (NPS) 和整体忠诚度。客户感到被倾听和支持,从而加强了 PDI 品牌关系。
- 成本降低 – PDIQ 处理了大部分重复性查询,使有限的支持人员能够专注于专家级别的案例,从而提高了生产力和士气。此外,PDIQ 构建在无服务器架构之上,可以自动扩展,同时最大限度地减少运营开销和成本。
- 业务灵活性 – 单一平台可以服务于不同的业务部门,他们可以通过配置各自的数据源来策划内容。
- 增量价值 – 每个新的内容源都增加了可衡量的价值,而无需重新设计系统。
PDI 正在计划中增加多项改进,以继续增强该应用程序,包括:
- 为新数据源(例如 GitHub)构建额外的爬虫配置。
- 构建 PDIQ 的代理实现,以集成到更大的复杂业务流程中。
- 增强文档理解能力,支持表格提取和结构保留。
- 为全球运营提供多语言支持。
- 使用混合检索技术改进相关性排名。
- 能够基于事件(例如源提交)调用 PDIQ。
结论
PDIQ 服务改变了 PDI Technologies 员工访问和使用企业知识的方式。通过使用 Amazon 无服务器服务,PDIQ 可以根据需求自动扩展、减少运营开销并优化成本。该解决方案独特的文件处理方法,包括动态令牌管理和自定义图像标题系统,代表了企业 RAG 系统中的一项重大技术创新。该架构在平衡性能、成本和可扩展性的同时,成功地维护了安全和身份验证要求。随着 PDI Technologies 继续扩展 PDIQ 的功能,他们对该架构如何适应新来源、格式和用例感到兴奋。
关于作者
 Samit Kumbhani 是 Amazon Web Services (AWS) 的高级解决方案架构师,在纽约市地区工作,拥有超过 18 年的经验。他目前与独立软件供应商 (ISV) 合作,构建高度可扩展、创新且安全的云解决方案。在工作之余,Samit 喜欢打板球、旅行和骑自行车。
Samit Kumbhani 是 Amazon Web Services (AWS) 的高级解决方案架构师,在纽约市地区工作,拥有超过 18 年的经验。他目前与独立软件供应商 (ISV) 合作,构建高度可扩展、创新且安全的云解决方案。在工作之余,Samit 喜欢打板球、旅行和骑自行车。
 Jhorlin De Armas 是 PDI Technologies 的 II 级架构师,负责在 Amazon Web Services (AWS) 上设计由 AI 驱动的平台。自 2024 年加入 PDI 以来,他设计了一个组合式 AI 服务,该服务使用 Amazon Bedrock、Aurora Serverless、AWS Lambda 和 DynamoDB 实现了可配置的助手、代理、知识库和护栏。Jhorlin 在构建企业软件方面拥有超过 18 年的经验,专长于以云为中心的架构、无服务器平台和 AI/ML 解决方案。
Jhorlin De Armas 是 PDI Technologies 的 II 级架构师,负责在 Amazon Web Services (AWS) 上设计由 AI 驱动的平台。自 2024 年加入 PDI 以来,他设计了一个组合式 AI 服务,该服务使用 Amazon Bedrock、Aurora Serverless、AWS Lambda 和 DynamoDB 实现了可配置的助手、代理、知识库和护栏。Jhorlin 在构建企业软件方面拥有超过 18 年的经验,专长于以云为中心的架构、无服务器平台和 AI/ML 解决方案。
 David Mbonu 是 Amazon Web Services (AWS) 的高级解决方案架构师,帮助水平业务应用 ISV 客户在 AWS 上构建和部署变革性解决方案。David 在软件、金融科技和公共云公司拥有超过 27 年的企业解决方案架构和系统工程经验。他最近的兴趣包括 AI/ML、数据战略、可观察性、弹性和安全。David 和他的家人居住在佐治亚州的 Sugar Hill。
David Mbonu 是 Amazon Web Services (AWS) 的高级解决方案架构师,帮助水平业务应用 ISV 客户在 AWS 上构建和部署变革性解决方案。David 在软件、金融科技和公共云公司拥有超过 27 年的企业解决方案架构和系统工程经验。他最近的兴趣包括 AI/ML、数据战略、可观察性、弹性和安全。David 和他的家人居住在佐治亚州的 Sugar Hill。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区