



📢 转载信息
原文作者:Iván Palomares Carrascosa
Image by Editor
# 引言
得益于大型语言模型(LLMs),我们现在拥有了像Gemini、ChatGPT和Claude这样令人印象深刻且极其有用的应用,仅举几例。然而,很少有人意识到,LLM背后的底层架构被称为Transformer。这种架构经过精心设计,以一种非常特殊的方式来“思考”——即处理描述人类语言的数据。您是否对全面了解这些所谓的Transformer内部发生了什么感兴趣呢?
本文将使用一种温和、易懂且相当非技术性的语气,描述LLM背后的Transformer模型如何分析用户提示等输入信息,以及它们如何逐字(或者说,逐个Token)生成连贯、有意义且相关的输出文本。
# 初始步骤:让机器理解语言
要掌握的第一个关键概念是,AI模型并不真正理解人类语言;它们只理解并操作数字,LLM背后的Transformer也不例外。因此,在Transformer能够深入处理文本之前,有必要将人类语言——即文本——转换为一种它可以完全理解的形式。
换句话说,在进入Transformer核心和最内层之前发生的最初几个步骤,主要集中在将原始文本转换为一种在底层保留了原始文本关键特性和特征的数值表示。让我们来检查这三个步骤。
使机器能够理解语言 (点击放大)
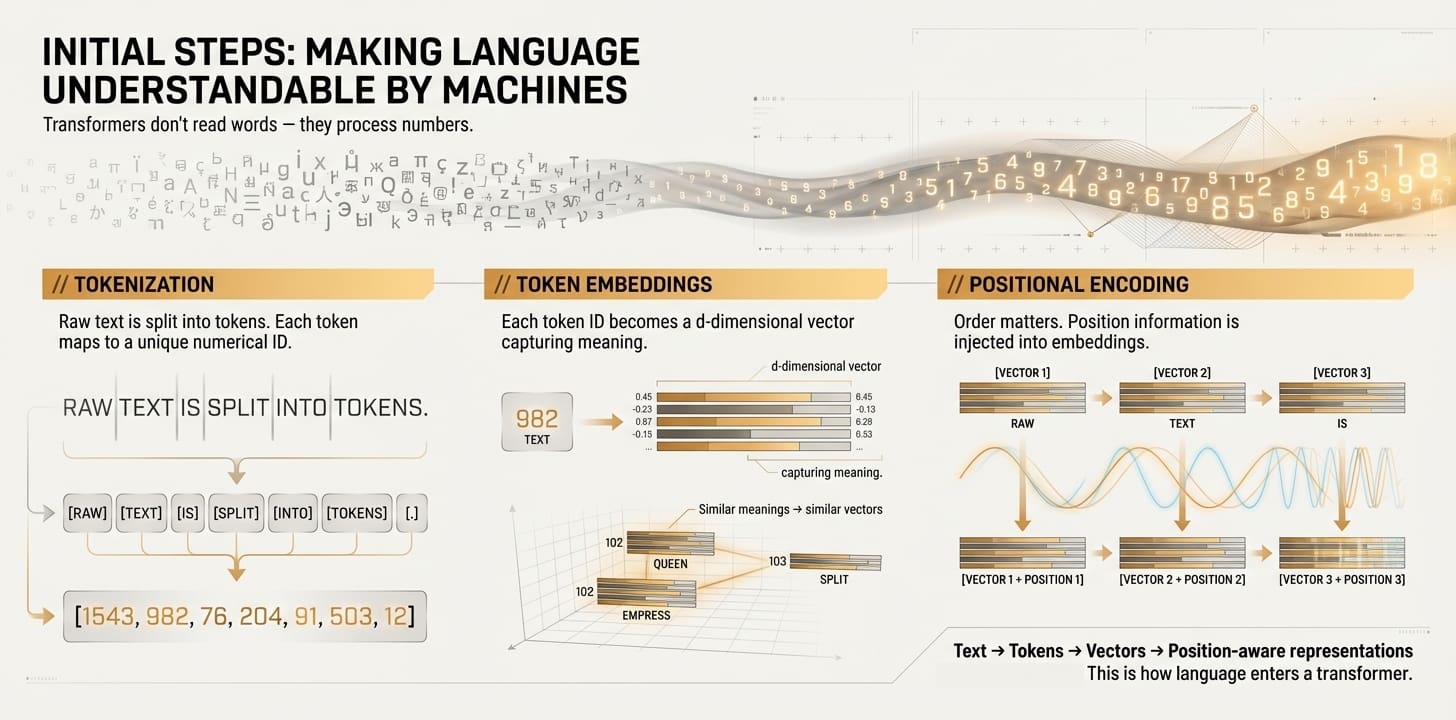
// 分词(Tokenization)
分词器是第一个登场的角色,它与Transformer模型协同工作,负责将原始文本分割成称为Token的小块。根据使用的分词器,这些Token在大多数情况下等同于单词,但Token有时也可能是单词的一部分或标点符号。此外,语言中的每个Token都有一个唯一的数字标识符。这时,文本就不再是文本,而是数字:所有操作都在Token级别进行,如本例所示,一个简单的分词器将包含五个单词的文本转换为五个Token标识符,每个单词对应一个:

文本分词为Token标识符
// Token嵌入(Token Embeddings)
接下来,每个Token ID被转换成一个d维向量,即一个大小为d的数字列表。一个Token的完整表示,即嵌入向量,就像是对该Token整体含义的描述,无论它是一个单词、单词的一部分还是标点符号。奇妙之处在于,与相似概念含义相关的Token,如queen(女王)和empress(女皇),将具有相似的嵌入向量。
// 位置编码(Positional Encoding)
到目前为止,Token嵌入包含的是一堆数字形式的信息,但这些信息仍与单个Token孤立地相关。然而,在像文本序列这样的“语言片段”中,不仅要知道它包含哪些单词或Token,还必须知道它们在文本中的位置。位置编码是一个过程,它通过使用数学函数,将关于其在原始文本序列中位置的一些额外信息注入到每个Token嵌入中。
# Transformer模型核心的转换过程
现在每个Token的数值表示都包含了关于其在文本序列中位置的信息,是时候进入Transformer模型主体结构的第一层了。Transformer是一个非常深层的架构,其中有许多复制的组件贯穿整个系统。Transformer层有两种类型——编码器层和解码器层——但为了简单起见,我们在本文中不会对它们做出细微的区别。只需知道,Transformer中存在两种类型的层即可,尽管它们有很多共同之处。
Transformer核心的转换过程 (点击放大)
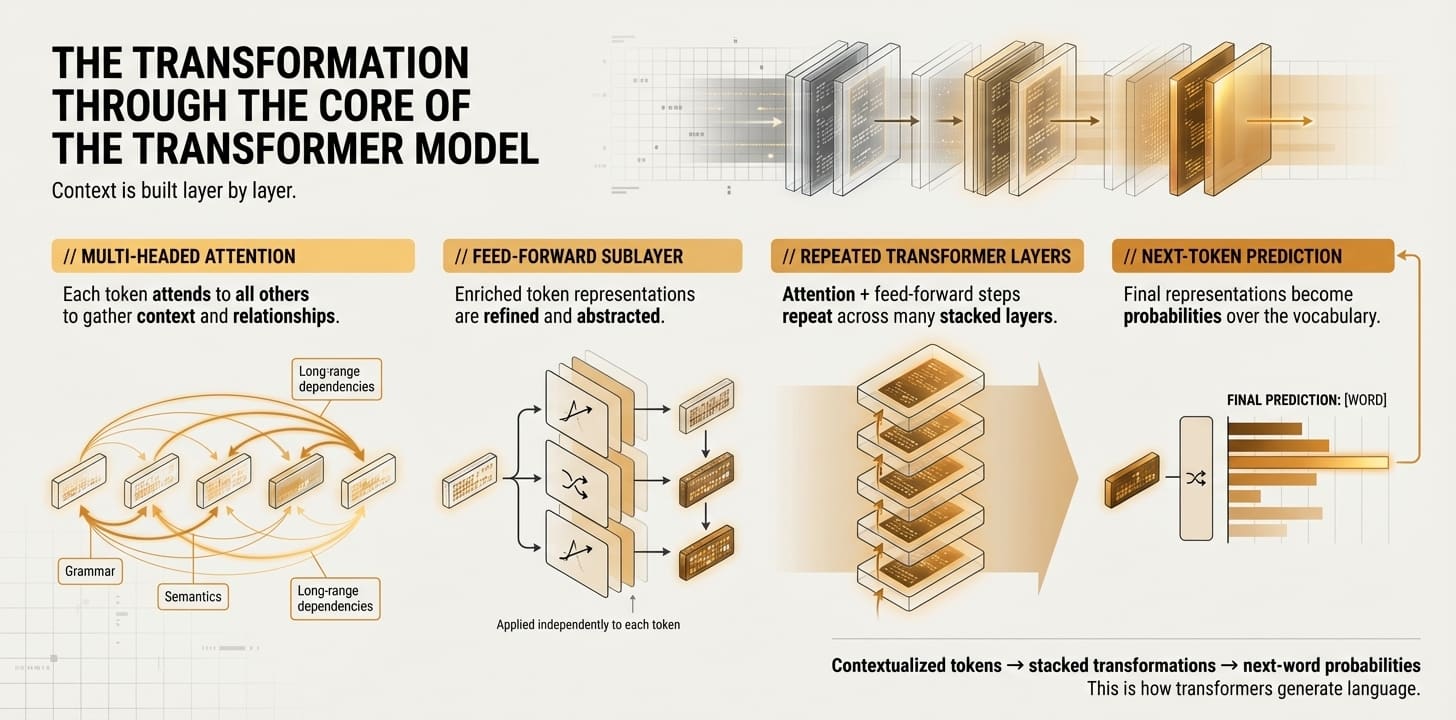
// 多头注意力(Multi-Headed Attention)
这是发生在Transformer层内的第一个主要子过程,也是与其它类型AI系统相比,Transformer模型最重要和最显著的特征。多头注意力是一种机制,它允许一个Token观察或“关注”序列中的其他Token。它收集并整合有用的上下文信息到其自身的Token表示中,即语法关系、词语之间(不一定相邻)的长期依赖关系或语义相似性等语言方面。总之,得益于这种机制,原始文本各部分相关性和关系等各种方面都能被成功捕获。一个Token表示通过这个组件后,它将获得关于自身及其所属文本更丰富、更具上下文感知的表示。
某些专为特定任务构建的Transformer架构,例如将文本从一种语言翻译成另一种语言,也通过这种机制分析Token之间可能的依赖关系,同时关注输入文本和迄今生成的(已翻译的)输出文本,如下所示:
翻译Transformer中的多头注意力
// 前馈神经网络子层(Feed-Forward Neural Network Sublayer)
简单来说,在经过注意力层之后,Transformer每个复制层内的第二个常见阶段是一组串联的神经网络层,它们进一步处理并帮助学习我们经过丰富表示的Token的附加模式。这个过程类似于进一步锐化这些表示,识别并加强相关的特征和模式。最终,这些层是用来逐步学习所处理的整个文本的通用、日益抽象的理解的机制。
通过以上两个步骤的交替重复多次,即重复的次数等于我们拥有的Transformer层数。
// 最终目的地:预测下一个词
在多次交替重复前两个步骤之后,来自初始文本的Token表示应该已经让模型获得了非常深入的理解,使其能够识别复杂而微妙的关系。此时,我们到达了Transformer堆栈的最后一个组件:一个特殊层,它将最终表示转换为词汇表中每个可能Token的概率。也就是说,我们根据沿途学到的所有信息,计算出目标语言中每个词成为Transformer模型(或LLM)应输出的下一个词的概率。模型最终选择概率最高的Token或词作为它为最终用户生成的输出的一部分。对于模型响应中要生成的每个词,整个过程都会重复一遍。
# 总结
本文通过一次温和的概念之旅,带您了解文本信息在LLM的标志性模型架构——Transformer中流动的过程。阅读完本文后,您或许能更好地理解像ChatGPT背后的模型内部发生了什么。
Iván Palomares Carrascosa是人工智能、机器学习、深度学习和LLM领域的领导者、作家、演讲者和顾问。他负责培训和指导他人如何在现实世界中利用AI。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区