



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/inference-open-source-models-blackwell-reduce-cost-per-token/
原文作者:Shruti Koparkar
医疗诊断洞察、交互式游戏中的角色对话、客服代表的自主解决方案。每一次由AI驱动的交互都建立在同一个智能单元之上:一个Token。
扩展这些AI交互需要企业考虑是否能负担得起更多的Tokens。答案在于更优的Tokenomics——其核心在于降低每个Token的成本。这一下降趋势正在各个行业中显现。最近的麻省理工学院研究发现,基础设施和算法效率每年可将前沿性能的推理成本降低高达10倍。
要理解基础设施效率如何改善Tokenomics,可以类比一台高速印刷机。如果这台印刷机在墨水、能源和机器本身的增量投入下,能产生10倍的产出,那么打印每一张纸的成本就会下降。同样,在AI基础设施上的投入可以带来远超成本增加的Token产出——从而导致每个Token的成本有意义地降低。
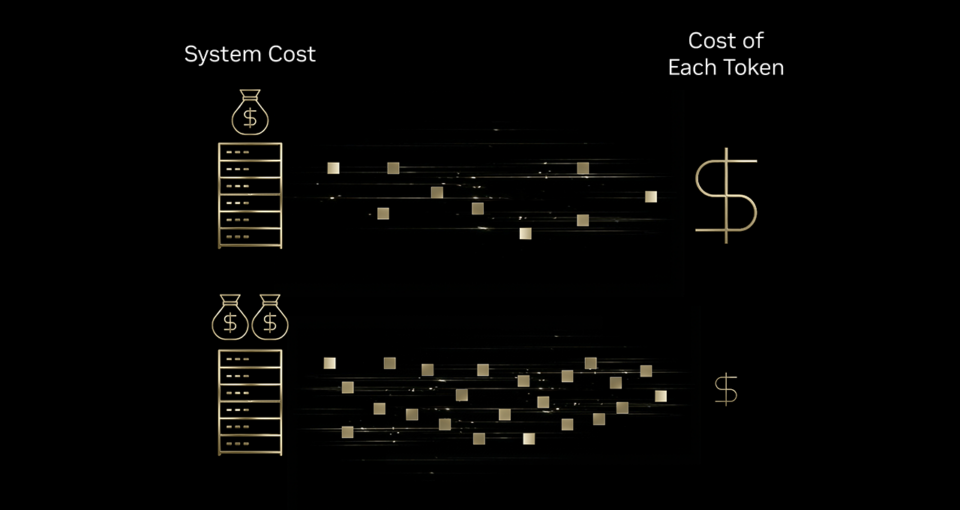
这就是为什么包括Baseten、DeepInfra、Fireworks AI和Together AI在内的领先推理提供商正在使用NVIDIA Blackwell平台,该平台帮助他们在与NVIDIA Hopper平台相比时,将每个Token的成本降低高达10倍。
这些提供商托管着已经达到前沿智能水平的先进开源模型。通过将开源前沿智能、NVIDIA Blackwell的极端软硬件协同设计以及他们自己的优化推理堆栈相结合,这些提供商正在为所有行业的企业带来显著的Token成本降低。
医疗保健 — Baseten 和 Sully.ai 将AI推理成本降低10倍
在医疗保健领域,诸如医疗编码、文档记录和保险表格管理等繁琐耗时的任务,侵占了医生与患者相处的时间。
Sully.ai通过开发能够处理医疗编码和记录等日常任务的“AI员工”来解决这个问题。随着公司平台的扩展,其专有的闭源模型带来了三个瓶颈:实时临床工作流程中不可预测的延迟、比收入增长更快的推理成本,以及对模型质量和更新控制能力的不足。
为克服这些瓶颈,Sully.ai 使用 Baseten 的模型 API,该API在NVIDIA Blackwell GPU上部署了如gpt-oss-120b等开源模型。Baseten 利用低精度NVFP4数据格式、NVIDIA TensorRT-LLM 库和NVIDIA Dynamo推理框架来实现优化推理。该公司选择NVIDIA Blackwell来运行其模型API,因为与NVIDIA Hopper平台相比,其每美元的吞吐量提高了2.5倍。
结果是,Sully.ai的推理成本下降了90%,与先前的闭源实现相比降低了10倍,同时生成医疗记录等关键工作流程的响应时间提高了65%。该公司目前已为医生节省了超过3000万分钟的时间,这些时间之前都浪费在数据输入和其他手动任务上。
游戏 — DeepInfra 和 Latitude 将每Token成本降低4倍
Latitude正在通过其AI Dungeon冒险故事游戏和即将推出的由AI驱动的角色扮演游戏平台Voyage,构建AI原生游戏未来。在Voyage中,玩家可以自由选择任何行动并创造自己的故事,来创建或体验世界。
该公司的平台使用大型语言模型来响应玩家的操作——但这带来了扩展挑战,因为每个玩家操作都会触发一次推理请求。成本随参与度而增加,而响应时间必须保持足够快,以保持体验的无缝性。

Latitude 在DeepInfra 的推理平台上运行大型开源模型,该平台由NVIDIA Blackwell GPU和TensorRT-LLM提供支持。对于一个大型专家混合(MoE)模型,DeepInfra将每百万Tokens的成本从NVIDIA Hopper平台的20美分降低到Blackwell上的10美分。转向Blackwell的原生低精度NVFP4格式,将该成本进一步削减至仅5美分——使每个Token的成本总体提高了4倍——同时保持了客户期望的准确性。
在DeepInfra的Blackwell驱动平台上运行这些大规模MoE模型,使Latitude能够在成本效益高的前提下,提供快速、可靠的响应。DeepInfra推理平台在可靠处理流量高峰的同时提供了这种性能,使Latitude能够在不影响玩家体验的情况下部署更强大的模型。
代理聊天 — Fireworks AI 和 Sentient Foundation 将AI成本降低高达50%
Sentient Labs专注于将AI开发者聚集在一起,构建强大的推理AI系统,这些系统都是开源的。目标是通过在安全自主、代理架构和持续学习方面的研究,加速AI解决更困难的推理问题。
其首个应用Sentient Chat,编排复杂的多代理工作流,并集成了社区提供的十多个专业AI代理。因此,Sentient Chat具有巨大的计算需求,因为单个用户查询可能会触发一系列自主交互,这通常会导致昂贵的底层基础设施开销。
为管理这种规模和复杂性,Sentient 使用运行在NVIDIA Blackwell上的Fireworks AI推理平台。通过Fireworks的Blackwell优化推理堆栈,Sentient 与其先前的基于Hopper的部署相比,实现了25%至50%的成本效率提升。
这种每GPU更高的吞吐量使得公司能够以相同的成本服务更多并发用户。该平台的扩展性支持了其在24小时内病毒式推出了180万的等候名单用户,并在单周内处理了560万次查询,同时保持了持续的低延迟。
客户服务 — Together AI 和 Decagon 推动成本降低6倍
带有语音AI的客户服务电话常常令人沮丧,因为即使是轻微的延迟也可能导致用户与座席同时发言、挂断电话或失去信任。
Decagon 为企业客户支持构建AI代理,其中AI驱动的语音是其要求最高的渠道。Decagon 需要基础设施能够在不可预测的流量负载下提供亚秒级响应,并且具有支持全天候语音部署的Tokenomics。

Together AI 在NVIDIA Blackwell GPU上为Decagon的多模型语音堆栈运行生产推理。两家公司在几项关键优化方面进行了合作:包括推测解码(训练较小的模型生成更快响应,而较大的模型在后台验证准确性)、缓存重复的对话元素以加速响应,以及构建自动扩展功能以处理流量激增而不会降低性能。
即使在处理每查询数千个Tokens时,Decagon 观察到的响应时间也低于400毫秒。与使用闭源专有模型相比,每个查询的成本(完成一次语音交互的总成本)降低了6倍。这是通过Decagon的多模型方法(部分开源,部分在NVIDIA GPU上内部训练)、NVIDIA Blackwell的极致协同设计以及Together优化的推理堆栈共同实现的。
通过极致协同设计优化Tokenomics
医疗保健、游戏和客户服务领域看到的显著成本节省是由NVIDIA Blackwell的效率驱动的。NVIDIA GB200 NVL72系统通过为推理MoE模型提供比NVIDIA Hopper低10倍的每Token成本的突破性指标,进一步扩大了这种影响。
NVIDIA 在跨越计算、网络和软件的堆栈每一层的极致协同设计,以及其合作伙伴生态系统,正在规模化地解锁每Token成本的大幅降低。
这一势头正随着NVIDIA Rubin平台的推出而持续——该平台集成了六个新的芯片到一个AI超级计算机中,旨在提供比Blackwell高10倍的性能和10倍低的Token成本。
探索NVIDIA 的全栈推理平台,了解更多关于它如何为AI推理提供更好的Tokenomics。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区