



📢 转载信息
原文链接:https://openai.com/index/netomi
原文作者:OpenAI
企业期望 AI 智能体能够可靠地处理复杂的、混乱的工作流程,默认遵守既定策略,能够在高负载下运行,并能展示其工作过程。
Netomi(在新窗口中打开)构建的系统能够达到这一高标准,服务于美国联合航空(United Airlines)和 DraftKings 等财富 500 强客户。其平台将 GPT‑4.1 用于低延迟、可靠的工具调用,将 GPT‑5.2 用于更深入的多步骤规划,所有操作都在一个经过严格控制的执行层内运行,旨在确保模型驱动的操作在真实的生产条件下保持可预测性。
以这种规模运行智能体系统,为 Netomi 提供了企业内部部署成功的蓝图。
Lesson 1: Build for real-world complexity, not idealized flows
单个企业请求很少只映射到一个 API。真实的工作流程通常跨越预订引擎、忠诚度数据库、CRM 系统、策略逻辑、支付和知识来源。数据通常不完整、相互冲突或具有时间敏感性。依赖于脆弱流程的系统在这种多变性面前会崩溃。
Netomi 设计其 Agentic OS,使 OpenAI 模型位于一个为处理这种程度的模糊性而构建的、受管制的编排管道的中心。该平台使用 GPT‑4.1 进行快速、可靠的推理和工具调用——这对于实时工作流程至关重要——而在需要多步骤规划或更深入推理时,则使用 GPT‑5.2。
“我们的目标是编排人类代理通常需要应对的许多系统,并在机器速度下安全地完成它。”
为确保在漫长而复杂的任务中智能体行为的一致性,Netomi 遵循 OpenAI 推荐的智能体提示模式:
- Persistence reminders(持久性提醒):帮助 GPT‑5.2 在漫长、多步骤的工作流程中保持推理能力
- Explicit tool-use expectations(明确的工具使用预期):通过引导 GPT‑4.1 在交易操作期间调用工具以获取权威信息,来抑制幻觉回答
- Structured planning(结构化规划):利用 GPT‑5.2 更深入的推理能力来概述和执行多步骤任务
- Agent-driven rich media decisions(智能体驱动的富媒体决策):依靠 GPT‑5.2 来检测并发出信号,指示工具调用何时应返回图像、视频、表单或其他丰富的多模态元素
这些模式共同帮助模型可靠地将非结构化请求映射到多步骤工作流程,并在不连续的交互中保持状态。
很少有行业像航空业那样清晰地暴露出多步骤推理的需求,因为一个交互通常跨越多个系统和策略层。一个简单的问题可能需要检查票价规则、重新计算忠诚度福利、发起机票更改,并与航班运营协调。
Mehta 说:“在航空业,情境每分钟都在变化。AI 必须推理客户所处的场景——而不仅仅是执行一个孤立的任务。这就是为什么情境感知比单纯的工作流程重要得多,也是为什么以情境为先导的集成架构至关重要。”
借助 GPT‑4.1 和 GPT‑5.2,Netomi 可以不断将这些模式扩展到更丰富的多步骤自动化中——使用这些模型不仅是为了回答问题,也是为了规划任务、排序动作以及协调一家大型航空公司所依赖的后端系统。
Lesson 2: Parallelize everything to meet enterprise latency expectations
在高压时刻——例如风暴期间重新预订、解决账单问题或应对需求的突然激增时——用户会放弃任何犹豫不决的系统。延迟决定了信任。
大多数 AI 系统失败的原因是它们按顺序执行任务:分类 → 检索 → 验证 → 调用工具 → 生成输出。Netomi 转而设计了并发性,利用 GPT‑4.1 的低延迟流式传输和工具调用稳定性。
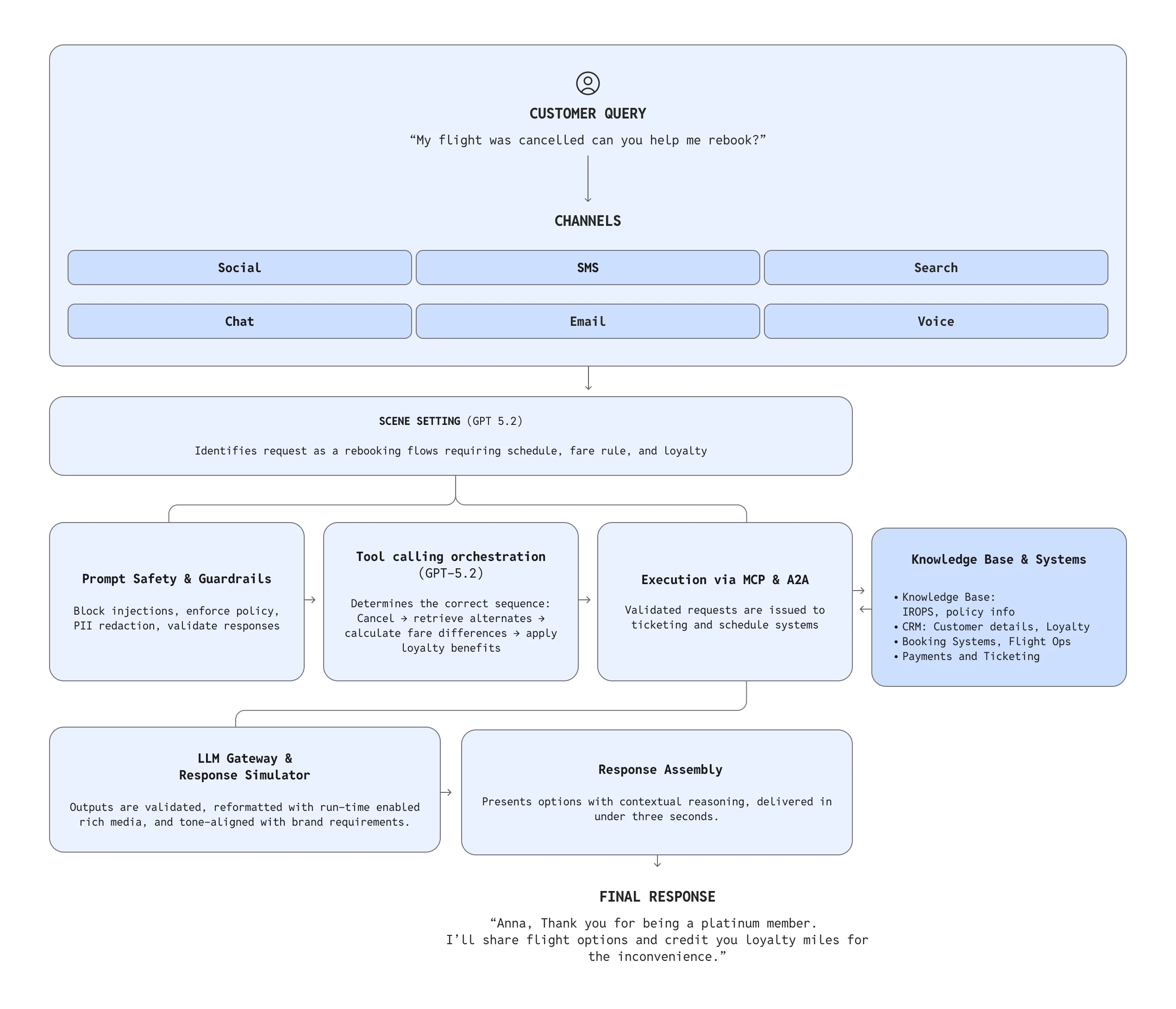
GPT‑4.1 提供了快速的首个 token 时间和可预测的工具调用行为,这使得该架构能够在规模上可行;而当需要更深层次的多步骤推理路径时,GPT‑5.2 则提供了支持。Netomi 的并发框架确保了整个系统,而不仅仅是模型本身,保持在关键延迟阈值之下。
这些并发需求并非航空业独有。任何暴露于突然、极端流量激增的系统都需要同样的架构纪律。例如,DraftKings 定期对该模型进行压力测试,在重大体育赛事期间,每秒并发客户请求量会激增至超过 40,000 次。
在这些事件中,Netomi 即使在工作流程涉及账户、支付、知识查询和监管检查的情况下,也能维持低于三秒的响应时间和 98% 的意图分类准确率。
DraftKings 的联合创始人兼运营总裁 Paul Liberman 表示:“在最关键的时刻,AI 是我们支持客户的核心和关键。Netomi 的平台帮助我们以敏捷性和精确性应对大规模的活动激增。”
在规模化应用中,Netomi 的并发模型依赖于 GPT‑4.1 的快速、可预测的工具调用能力,这使得多步骤工作流程在极端负载下仍能保持响应速度。
Lesson 3: Make governance an intrinsic part of the runtime
企业级 AI 必须在设计上就是可信赖的,治理机制必须直接编织到运行时中——而不是作为外部层添加。
当意图置信度低于阈值,或者请求无法以高确定性分类时,Netomi 的治理机制就会启动,以确定如何处理该请求,确保系统从自由形式的生成退回到受控的执行路径。
在技术层面,治理层处理以下事项:
- Schema validation(模式验证):在执行前验证每个工具调用是否符合预期的参数和 OpenAPI 合同
- Policy enforcement(策略执行):在推理和工具使用期间,内联应用主题过滤器、品牌限制和合规性检查
- PII protection(个人身份信息保护):在预处理和响应处理中检测和屏蔽敏感数据
- Deterministic fallback(确定性回退):在意图、数据或工具调用存在歧义时,路由回已知的安全行为
- Runtime observability(运行时可观测性):暴露 token 跟踪、推理步骤和工具链日志,用于实时检查和调试
在牙科保险等高度管制的领域,这种治理是不可或缺的。一家 Netomi 的保险业客户每年处理近 200 万次供应商请求,涵盖所有 50 个州,包括资格检查、福利查询和理赔状态查询,其中任何一个错误响应都可能导致下游的监管风险或服务风险。
在公开注册期间,当审查和需求量达到顶峰时,该公司需要 AI 在运行时本身就能强制执行策略。Netomi 的架构能够满足这一复杂要求。
Mehta 说:“我们构建系统的目的是,如果智能体达到不确定状态,它就知道如何安全地退避。治理不是附加上去的——它是运行时的组成部分。”
A blueprint for building agentic systems that work for the enterprise
Netomi 的发展历程展示了赢得企业信任所需的条件:为复杂性而构建,通过并行化满足延迟要求,并将治理融入每个工作流程。OpenAI 模型构成了推理的骨干,而 Netomi 的系统工程则确保了智能在操作上是安全的、可审计的,并且已为财富 500 强环境做好了准备。
这些原则帮助 Netomi 扩展到一些世界上要求最苛刻的行业——并为任何希望将智能体 AI 转化为生产级基础设施的初创公司提供蓝图。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区