



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/optional-data-center-fleet-management-software/
原文作者:NVIDIA Newsroom
随着AI基础设施的规模和复杂性不断增长,数据中心运营商需要持续了解性能、温度和功耗等因素。这些洞察力使数据中心运营商能够主动监控和调整大规模分布式系统的配置,确保这些系统以最高效率和可靠性运行。
英伟达正在开发一个用于可视化和监控英伟达GPU集群的软件解决方案——为云合作伙伴和企业提供一个洞察仪表板,帮助他们提高整个计算基础设施中GPU的正常运行时间。
该服务是一种可选的、由客户安装的服务,用于监控GPU使用情况、配置和错误。它将包括一个开源的客户端软件代理——这是英伟达持续支持开放、透明软件的一部分,旨在帮助客户最大限度地利用其GPU驱动的系统。
通过该服务,数据中心运营商将能够:
- 跟踪功耗峰值,以在最大化每瓦性能的同时保持在能源预算内。
- 监控整个集群的利用率、内存带宽和互连健康状况。
- 及早检测热点和气流问题,以避免热节流和组件过早老化。
- 确认一致的软件配置和设置,以确保可复现的结果和可靠的运行。
- 发现错误和异常情况,及早识别故障部件。
这些功能可以帮助企业和云提供商可视化其GPU集群,解决系统瓶颈,优化生产力,从而获得更高的投资回报。
这项可选服务通过每个GPU系统与外部云服务通信并共享GPU指标,提供实时监控。英伟达GPU不具备硬件跟踪技术、禁用开关(kill switches)和后门。
开源代理为数据中心所有者提供洞察
该服务将包含一个客户可以安装的客户端软件代理,用于将节点级GPU遥测数据流式传输到托管在英伟达NGC上的门户。客户将能够按计算区域(注册在相同物理或云位置的节点组)或全局地在仪表板中可视化其GPU集群利用率。
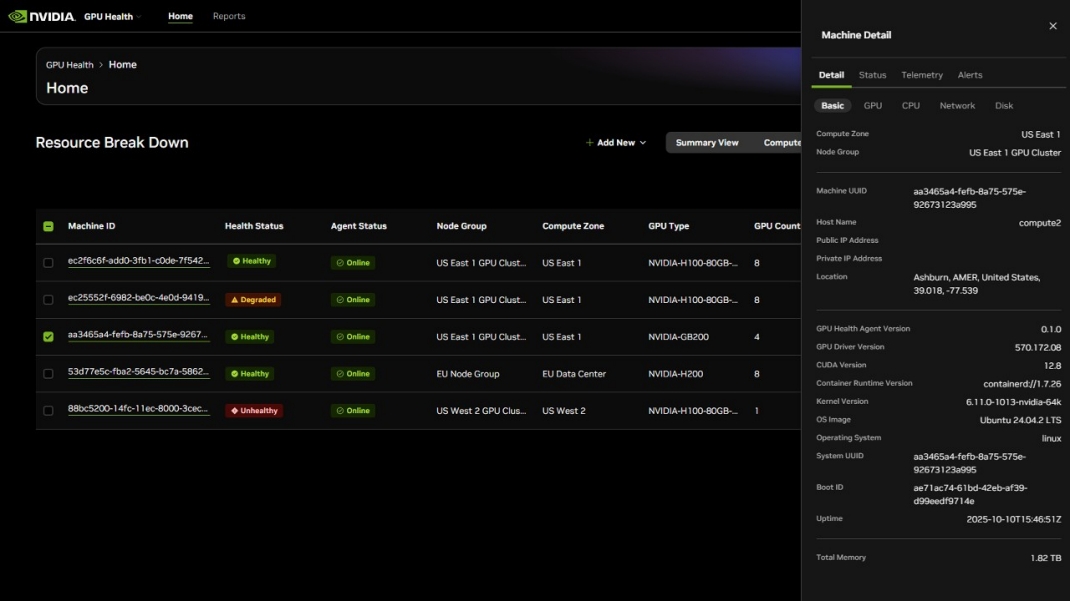
该客户端工具代理也计划开源,提供透明度和可审计性。它将为客户如何将英伟达工具集成到自己的GPU基础设施监控解决方案中提供一个工作示例——无论是针对关键计算集群还是整个集群。
该软件提供了对公司GPU库存的洞察,但不能修改GPU配置或底层操作。它提供的是客户管理和可定制的只读遥测数据。
该服务还将允许客户生成详细说明GPU集群信息的报告。
随着AI应用的数量和复杂性不断增长,现代AI基础设施管理正在不断发展以跟上步伐。随着AI正在彻底改变每个行业和应用,确保AI数据中心处于最佳运行状态至关重要。这项软件服务正是为此目的而推出的。
注册参加3月16日至19日在加利福尼亚州圣何塞举行的英伟达GTC大会,了解更多信息。
请参阅有关软件产品信息的声明。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区