



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/03/25/rl-av_smoothing/
原文作者:BAIR Berkeley AI Research
我们在高峰时段的高速公路上部署了100辆由强化学习(RL)控制的汽车,目的是为每个人平抑拥堵和减少燃料消耗。我们的目标是解决那些通常没有明确原因但会导致拥堵和显著能源浪费的“走走停停”(stop-and-go)波。为了训练高效的交通流平滑控制器,我们构建了快速、数据驱动的仿真环境,让RL智能体与之交互,学习在保持吞吐量和在人类驾驶员周围安全运行的同时,最大化能源效率。
总体而言,一小部分控制良好的自动驾驶汽车(AV)就足以显著改善道路上所有驾驶员的交通流量和燃油效率。 此外,所训练的控制器被设计成可以在大多数现代车辆上部署,以去中心化的方式运行,并依赖于标准的雷达传感器。在我们的最新论文中,我们探讨了将RL控制器从仿真扩展到实地部署的挑战,这一过程贯穿了这次100辆车的实验。
幻影拥堵的挑战

一个“走走停停”波在高速公路交通中向后移动。
如果你开车,你一定体验过“走走停停”波的令人沮丧之处,这些看似莫名其妙的交通减速,它们凭空出现,然后又突然消失。这些波浪通常是由我们驾驶行为中的微小波动引起的,这些波动在交通流中被放大。我们自然会根据前方的车辆调整自己的速度。如果间隙变大,我们会加速以跟上;如果它们刹车,我们也会减速。但由于我们有非零的反应时间,我们可能会比前车刹车稍微用力一点。后面的驾驶员也做同样的事情,这种现象不断放大。随着时间的推移,最初微不足道的减速变成后面交通流中的完全停车。这些波浪会逆着车流方向传播,由于频繁的加速,导致能源效率大幅下降,同时伴随着一氧化碳排放量的增加和事故风险的上升。
这并非孤立现象!当交通密度超过某个临界阈值时,这些波浪在繁忙的道路上无处不在。那么我们如何解决这个问题呢?传统的方法,如匝道控制和可变限速,试图管理交通流,但它们通常需要昂贵的基础设施和集中协调。一种更具可扩展性的方法是使用AV,它可以实时动态调整驾驶行为。然而,仅仅将AV插入到人类驾驶员中间是不够的:它们还必须以更智能的方式驾驶,为所有人改善交通,这就是RL发挥作用的地方。
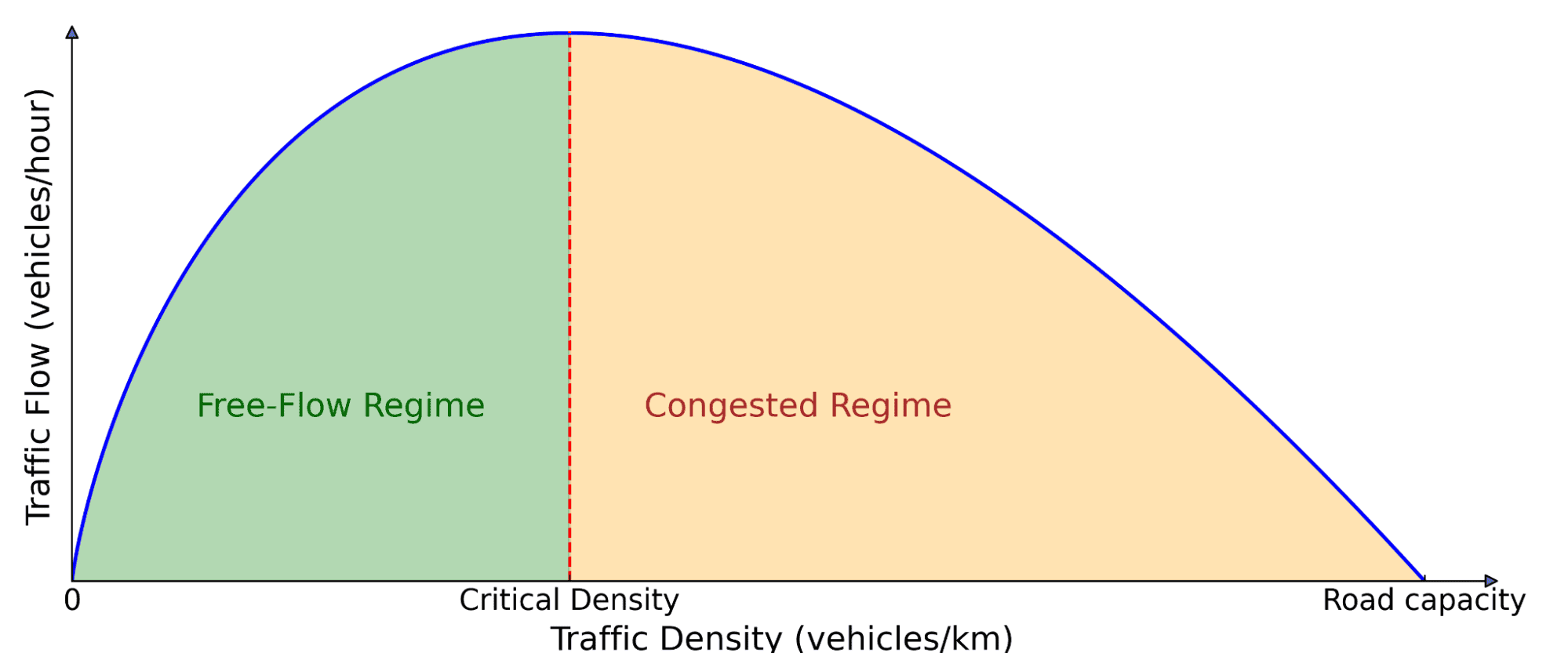
交通流基本图。道路上的汽车数量(密度)影响着前进的交通量(流量)。在低密度下,增加更多的汽车会增加流量,因为更多的车辆可以通过。但超过临界阈值后,汽车开始互相阻碍,导致拥堵,此时增加更多的汽车实际上会减慢整体移动速度。
用于平抑波浪的强化学习AV
RL是一种强大的控制方法,智能体通过与环境的交互来学习最大化奖励信号。智能体通过试错收集经验,从错误中学习,并随着时间的推移而改进。在我们的案例中,环境是一个混合自主交通场景,其中AV学习驾驶策略来抑制“走走停停”波,并减少它们自身和附近人工驾驶车辆的燃料消耗。
训练这些RL智能体需要在具有逼真交通动态的快速仿真环境中进行,这些仿真能够复制高速公路的“走走停停”行为。为此,我们利用了在田纳西州纳什维尔附近的24号州际公路(I-24)收集的实验数据,并用这些数据构建了仿真环境,其中车辆回放高速公路轨迹,产生不稳定的交通,而后面的AV则学习如何平滑这种不稳定性。
仿真回放了一条表现出数个“走走停停”波的高速公路轨迹。
我们在设计AV时考虑了部署因素,确保它们仅使用关于自身和前方车辆的基本传感器信息即可运行。观测数据包括AV的速度、前车的速度以及它们之间的空间间隙。根据这些输入,RL智能体然后为AV指定瞬时加速度或目标速度。仅使用这些局部测量值的关键优势在于,RL控制器可以以去中心化的方式部署在大多数现代车辆上,而无需额外基础设施。
奖励设计
最具挑战性的部分是设计一个奖励函数,当其被最大化时,能够与我们希望AV实现的各种目标保持一致:
- 波浪平滑: 减少“走走停停”的振荡。
- 能源效率: 降低所有车辆的燃料消耗,而不仅仅是AV。
- 安全: 确保合理的跟车距离并避免急刹车。
- 驾驶舒适性: 避免激进的加速和减速。
- 遵守人类驾驶规范: 确保“正常”的驾驶行为,不让周围的驾驶员感到不适。
平衡这些目标是困难的,因为必须找到每个项的合适系数。例如,如果最小化燃料消耗在奖励中占主导地位,RL AV会学会停在高速公路中间,因为那在能源上是最优的。为了防止这种情况,我们引入了动态最小和最大间隙阈值,以确保安全合理的行为,同时优化燃油效率。我们还惩罚了AV后方人工驾驶车辆的燃料消耗,以阻止AV学习一种自私的行为,即以牺牲周围交通为代价来优化自身的节能。
仿真结果
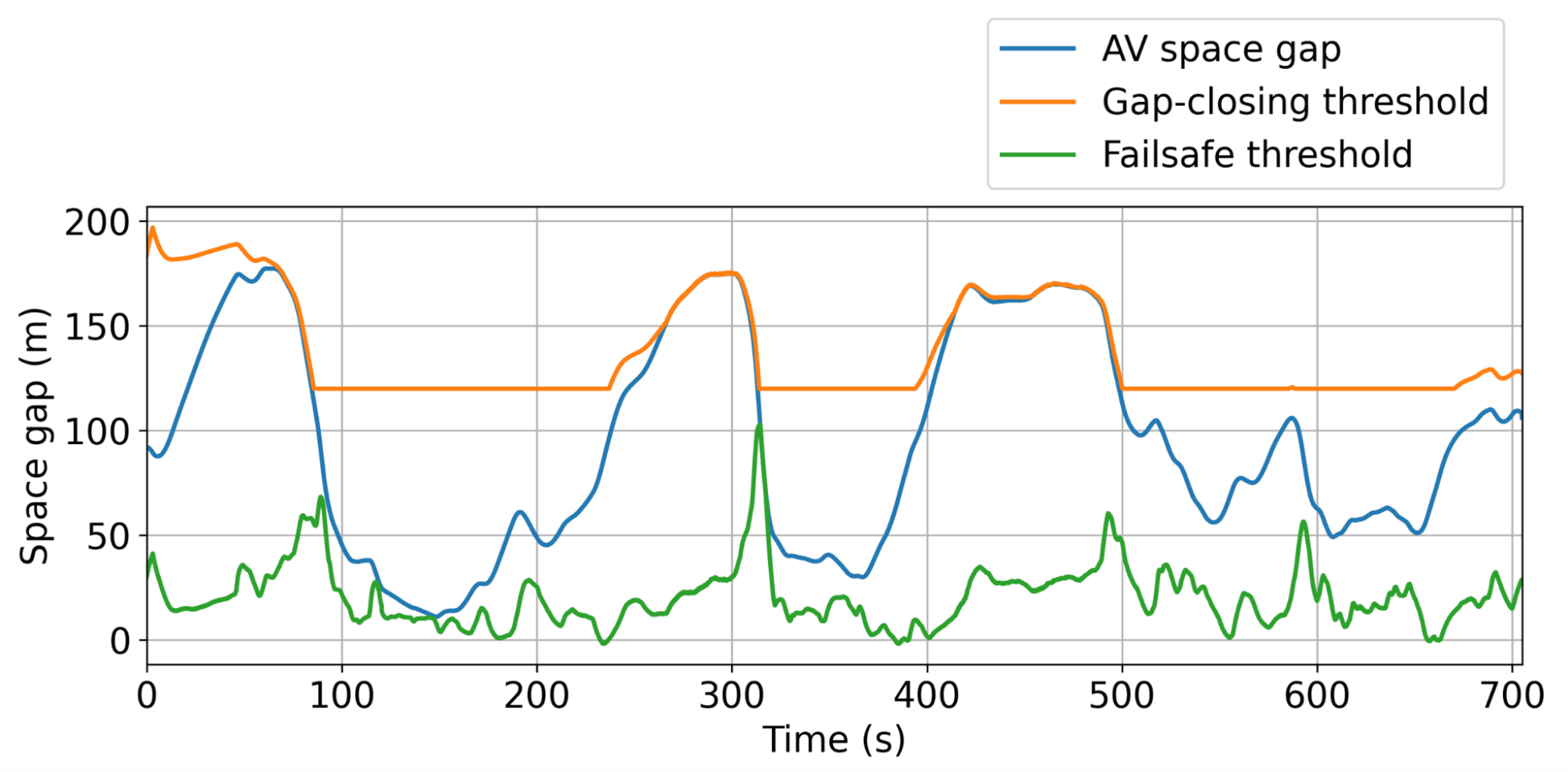
动态最小和最大间隙阈值的示意图,在这些阈值内,AV可以自由运行,以尽可能高效地平滑交通。
AV学习到的典型行为是保持比人类驾驶员稍大的间隙,使它们能够更有效地吸收即将到来的、可能突然的交通减速。在仿真中,这种方法在最拥堵的情况下,使所有道路使用者获得了高达20%的显著节油,而道路上只有不到5%的AV。而且这些AV不必是特殊的车辆!它们可以只是配备了智能自适应巡航控制(ACC)的标准消费类汽车,这也是我们进行大规模测试的内容。
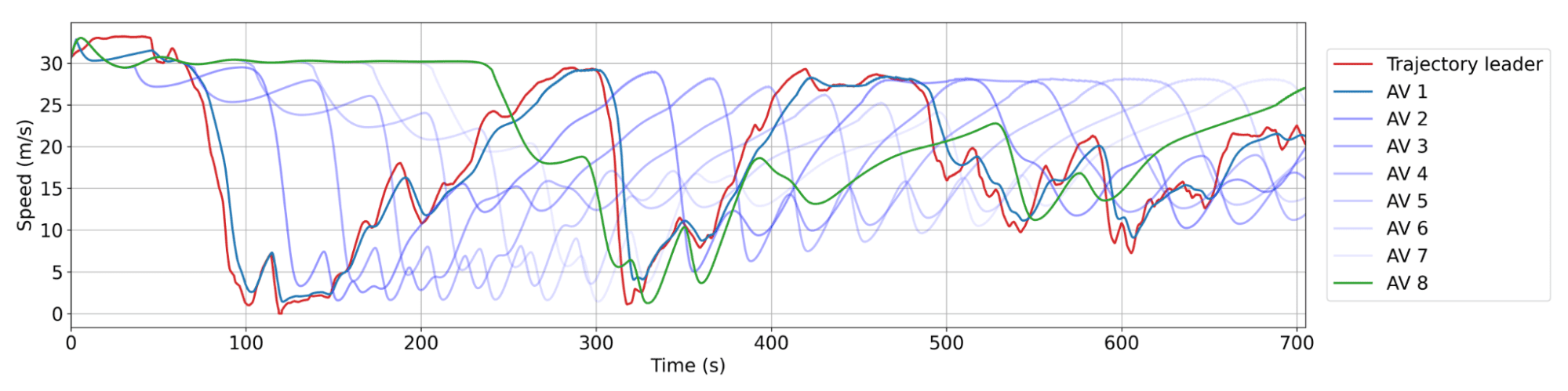 RL AV的平滑行为。红色:来自数据集的人类轨迹。蓝色:车队中连续的AV,其中AV 1是紧跟在人类轨迹后方的。AV之间通常有20到25辆人工驾驶车辆。每个AV减速的幅度或加速的快慢都比其前车小,从而随着时间的推移导致波幅减小,实现节能。
RL AV的平滑行为。红色:来自数据集的人类轨迹。蓝色:车队中连续的AV,其中AV 1是紧跟在人类轨迹后方的。AV之间通常有20到25辆人工驾驶车辆。每个AV减速的幅度或加速的快慢都比其前车小,从而随着时间的推移导致波幅减小,实现节能。
100辆AV现场测试:将RL大规模部署


实验周期间,我们的100辆车停在我们的运营中心。
鉴于有前景的仿真结果,自然而然的下一步是将差距从仿真桥接到高速公路。我们将训练好的RL控制器部署在I-24上100辆车上,在连续几天的早高峰时段进行测试。这项被称为MegaVanderTest的大规模实验,是有史以来规模最大的混合自主交通平滑实验。
在现场部署RL控制器之前,我们对其进行了广泛的仿真训练和评估,并在硬件上进行了验证。总的来说,部署的步骤包括:
- 数据驱动仿真训练: 我们使用I-24的高速公路交通数据创建了一个具有真实波浪动态的训练环境,然后在一系列新的交通场景中验证训练好的智能体的性能和鲁棒性。
- 硬件部署: 在机器人软件中验证后,训练好的控制器被上传到汽车上,能够控制车辆设定的速度。我们通过车辆的车载巡航控制系统进行操作,该系统充当低级安全控制器。
- 模块化控制框架: 测试中的一个关键挑战是没有访问前车信息传感器。为了克服这一点,RL控制器被集成到一个分层系统中,即MegaController,该系统结合了考虑下游交通状况的速度规划器指南,并将RL控制器作为最终决策者。
- 硬件验证: RL智能体被设计成在一个大多数车辆由人工驾驶的环境中运行,需要鲁棒的策略来适应不可预测的行为。我们通过在仔细的人工监督下在道路上驾驶RL控制的车辆来验证这一点,并根据反馈对控制进行更改。
 100辆车中的每一辆都连接到一个Raspberry Pi,RL控制器(一个小型神经网络)部署在上面。
100辆车中的每一辆都连接到一个Raspberry Pi,RL控制器(一个小型神经网络)部署在上面。
 RL控制器直接控制车载自适应巡航控制(ACC)系统,设定其速度和期望的跟车距离。
RL控制器直接控制车载自适应巡航控制(ACC)系统,设定其速度和期望的跟车距离。
验证完成后,RL控制器被部署在100辆车上,并在I-24的早高峰时段进行了驾驶。周围的交通对实验一无所知,确保了驾驶员行为的无偏性。实验期间,数据是通过沿高速公路布置的数十个高架摄像头收集的,通过计算机视觉管道提取了数百万条单独的车辆轨迹。在这些轨迹上计算的指标表明,AV周围的燃料消耗有所下降,这与仿真结果和先前较小规模的验证部署的预期一致。例如,我们可以观察到,人们离我们的AV越近,他们平均消耗的燃料似乎就越少(这是使用校准的能源模型计算的):
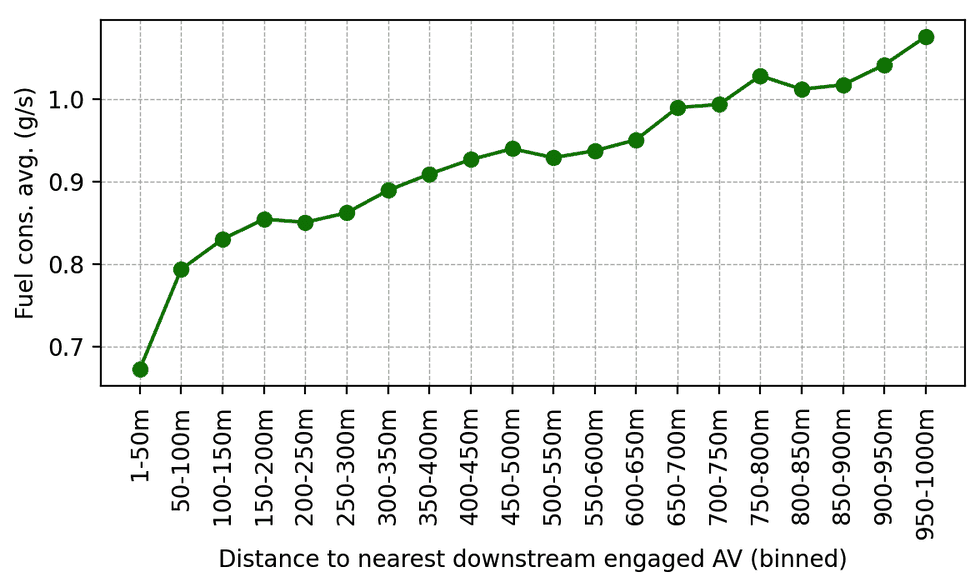
平均燃料消耗与下游交通中最近的、参与实验的RL控制AV的距离的关系图。随着人工驾驶员在AV后方距离的增加,他们的平均燃料消耗也随之增加。
衡量的另一种方法是衡量速度和加速度的方差:方差越低,波的幅度应该越小,这与我们在现场测试数据中观察到的相符。总的来说,尽管从大量的摄像机视频数据中获得精确测量很复杂,但我们观察到受控汽车周围的能源节省达到了15%到20%的趋势。
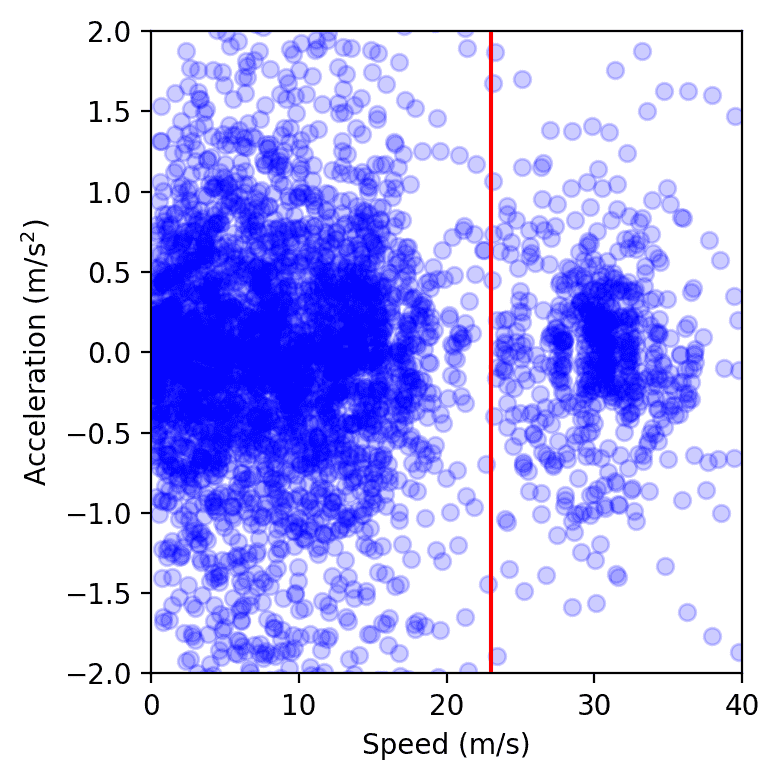
实验中某一天的所有高速公路车辆的数据点,在速度-加速度空间中绘制。红色线左侧的集群代表拥堵,右侧的集群代表自由流动。我们观察到,存在AV时,拥堵集群较小,测量方法是通过计算软凸包的面积或拟合高斯核。
最后的思考
100辆车的现场操作测试是去中心化的,AV之间没有明确的合作或通信,这反映了当前的自主部署,使我们离更平稳、更节能的高速公路又近了一步。然而,仍有巨大的改进潜力。将仿真扩展得更快、更准确,并使用更好的人类驾驶模型,对于弥合仿真到现实的差距至关重要。为AV配备额外的交通数据,无论是通过先进的传感器还是集中规划,都可以进一步提高控制器的性能。例如,虽然多智能体RL在改善协作控制策略方面很有前景,但启用AV之间通过5G网络进行显式通信如何能进一步提高稳定性和进一步减轻“走走停停”波仍然是一个悬而未决的问题。至关重要的是,我们的控制器与现有的自适应巡航控制(ACC)系统无缝集成,使得大规模现场部署成为可能。配备智能交通平滑控制的车辆越多,我们道路上看到的波浪就越少,这意味着为所有人带来了更少的污染和燃料节省!
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区