



📢 转载信息
原文链接:https://www.kdnuggets.com/top-5-open-source-llm-evaluation-platforms
原文作者:Kanwal Mehreen

Image by Author
# Introduction
每当您有一个关于大型语言模型(LLM)应用的新想法时,都必须对其进行适当的评估,以了解其性能。没有评估,就很难确定应用程序的运行效果。然而,大量基准、指标和工具(通常每个工具都有自己的脚本)可能会使管理评估过程变得极其困难。幸运的是,开源开发者和公司不断发布新的框架来协助解决这一挑战。
虽然有许多选择,但本文将分享我个人最喜欢的LLM评估平台。此外,文末还附有一个包含LLM评估丰富资源的“黄金知识库”链接。
# 1. DeepEval

DeepEval是一个专门用于测试LLM输出的开源框架。它易于使用,工作方式类似于Pytest。您为提示和预期输出编写测试用例,DeepEval会计算各种指标。它包含30多种内置指标(正确性、一致性、相关性、幻觉检查等),适用于单轮和多轮LLM任务。您还可以使用本地运行的LLM或自然语言处理(NLP)模型来构建自定义指标。
它还允许您生成合成数据集。它适用于任何LLM应用程序(聊天机器人、检索增强生成(RAG)管道、智能体等),以帮助您对模型行为进行基准测试和验证。另一个有用的功能是能够对LLM应用程序进行安全扫描,以检测安全漏洞。它在快速发现提示漂移或模型错误等问题方面非常有效。
# 2. Arize (AX & Phoenix)
Arize为LLM可观测性和评估提供了免费增值平台(Arize AX)和开源对应产品(Arize-Phoenix)。Phoenix完全开源且可自托管。您可以记录每一次模型调用、运行内置或自定义的评估器、对提示进行版本控制,并对输出进行分组,以便快速发现故障。它已为生产环境做好准备,具有异步工作进程、可扩展存储和以OpenTelemetry(OTel)为先的集成。这使得将评估结果轻松插入到您的分析管道中变得轻而易举。它非常适合希望完全控制或在受监管环境中工作的团队。
Arize AX提供了其产品的社区版本,具有许多相同的功能,并提供付费升级,以供大规模运行LLM的团队使用。它使用与Phoenix相同的追踪系统,但增加了企业功能,如SOC 2合规性、基于角色的访问控制、自带密钥(BYOK)加密以及气隙部署。AX还包含Alyx,一个AI助手,可以分析追踪、聚类故障并起草后续评估,以便您的团队可以快速采取行动,这是免费产品的一部分。您可以在一个地方获得仪表板、监控器和警报。这两种工具都使您更容易发现智能体何时出现问题,允许您创建数据集和实验,并在不使用多个工具的情况下进行改进。
# 3. Opik
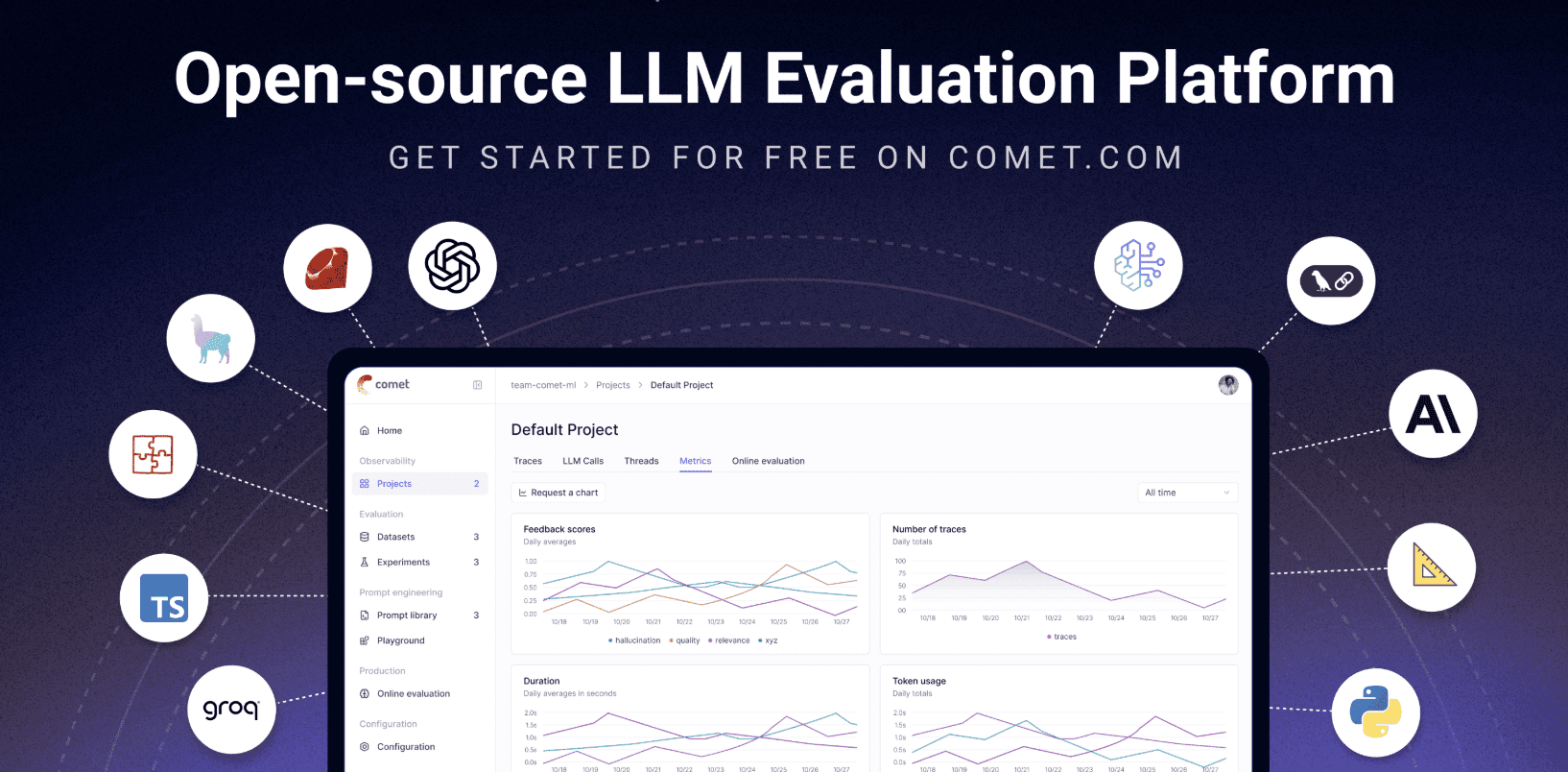
(来自Comet的)Opik是一个开源LLM评估平台,专为AI应用的端到端测试而构建。它可以让您记录每次LLM调用的详细追踪信息、对其进行注释,并在仪表板中可视化结果。您可以运行自动化的LLM仲裁指标(用于事实性、毒性等)、试验不同的提示,并注入安全护栏(如屏蔽个人身份信息(PII)或阻止不希望的主题)。它还与持续集成和持续交付(CI/CD)管道集成,因此您可以在每次部署时添加测试以捕获问题。它是持续改进和保护LLM管道的全面工具包。
# 4. Langfuse

Langfuse是另一个专注于可观测性和评估的开源LLM工程平台。它会自动捕获LLM调用期间发生的所有事情(输入、输出、API调用等),以提供完整的可追溯性。它还提供集中式提示版本控制和提示游乐场等功能,您可以在其中快速迭代输入和参数。
在评估方面,Langfuse支持灵活的工作流程:您可以使用LLM作为仲裁指标、收集人工注释、使用自定义测试集运行基准测试,并跨不同应用版本跟踪结果。它甚至提供用于生产监控的仪表板,并允许您运行A/B实验。它非常适合既需要开发人员用户体验(UX)(游乐场、提示编辑器)又需要完全了解已部署LLM应用程序的团队。
# 5. Language Model Evaluation Harness

(来自EleutherAI的)Language Model Evaluation Harness是一个经典的开源基准测试框架。它将数十个标准的LLM基准测试(超过60个任务,如Big-Bench、大规模多任务语言理解(MMLU)、HellaSwag等)打包到一个库中。它支持通过Hugging Face Transformers、GPT-NeoX、Megatron-DeepSpeed、vLLM推理引擎,甚至是OpenAI或TextSynth等API加载的模型。
它是Hugging Face Open LLM Leaderboard的基础,因此被研究界使用并被数百篇论文引用。它不专门用于“以应用为中心”的评估(如追踪智能体);相反,它在许多任务上提供了可再现的指标,因此您可以衡量模型与已发布基线的性能有多好。
# Wrapping Up (and a Gold Repository)
这里的每种工具都有其优势。如果您想在本地运行测试并检查安全问题,DeepEval很合适。Arize通过Phoenix(用于自托管设置)和AX(用于企业规模)为您提供深入的可视性。Opik非常适合端到端测试和改进智能体工作流程。Langfuse使追踪和管理提示变得简单。最后,LM Evaluation Harness非常适合跨大量标准学术任务进行基准测试。
为了让事情更简单,Andrei Lopatenko的LLM Evaluation知识库将所有主要的LLM评估工具、数据集、基准测试和资源收集在一个地方。如果您想要一个用于测试、评估和改进模型的单一中心,那就是它。
Kanwal Mehreen是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交叉领域怀有深厚的激情。她是电子书《最大化ChatGPT的生产力》的合著者。作为2022年亚太地区的谷歌一代学者,她倡导多样性和学术卓越。她还被认可为Teradata技术多样性学者、Mitacs全球链接研究学者和哈佛WeCode学者。Kanwal是变革的热心倡导者,创立了FEMCodes以赋能STEM领域的女性。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区