



📢 转载信息
原文作者:Wei Teh, Lana Zhang, and Yanyan Zhang
媒体和娱乐、广告、教育和企业培训内容结合了视觉、音频和动态元素来讲述故事和传达信息,这比文本复杂得多,因为文本中的单个词语具有明确的含义。这给需要理解视频内容的人工智能系统带来了独特的挑战。视频内容是多维的,结合了视觉元素(场景、对象、动作)、时间动态(运动、过渡)、音频组件(对话、音乐、音效)和文本叠加(字幕、标题)。这种复杂性带来了重大的业务挑战,因为组织难以搜索视频档案、定位特定场景、自动对内容进行分类以及从媒体资产中提取见解以实现有效的决策制定。
该模型通过创建一个独立于内容模态的多向量架构来解决这个问题。模型不是将所有信息强行压缩到一个向量中,而是生成专门的表示形式。这种方法保留了视频数据的丰富、多方面的特性,从而能够在视觉、时间及音频维度上进行更准确的分析。
Amazon Bedrock 已经扩展了其功能,通过同步推理支持带有实时文本和图像处理的 TwelveLabs Marengo Embed 3.0 模型。通过这种集成,企业可以使用自然语言查询实现更快的视频搜索功能,同时还支持通过复杂的图像相似度匹配实现交互式产品发现。
在本文中,我们将展示在 Amazon Bedrock 上可用的 TwelveLabs Marengo 嵌入模型如何通过多模态 AI 增强视频理解能力。我们将使用来自 Marengo 模型的嵌入,并以 Amazon OpenSearch Serverless 作为向量数据库,构建一个视频语义搜索和分析解决方案,以实现超越简单元数据匹配的智能内容发现功能。
理解视频嵌入
嵌入是捕获数据在更高维度空间中语义含义的密集向量表示。您可以将其视为编码内容精髓的数字指纹,以便机器可以理解和比较。对于文本,嵌入可能会捕获“国王”和“王后”是相关概念,或者“巴黎”和“法国”具有地理关系。对于图像,即使它们看起来不同,嵌入也可以理解 金毛猎犬 和 拉布拉多犬 都是狗。下图的热力图显示了这些句子片段之间的语义相似度得分:“两个人正在交谈”、“一个男人和一个女人正在说话”以及“猫和狗是可爱的动物”。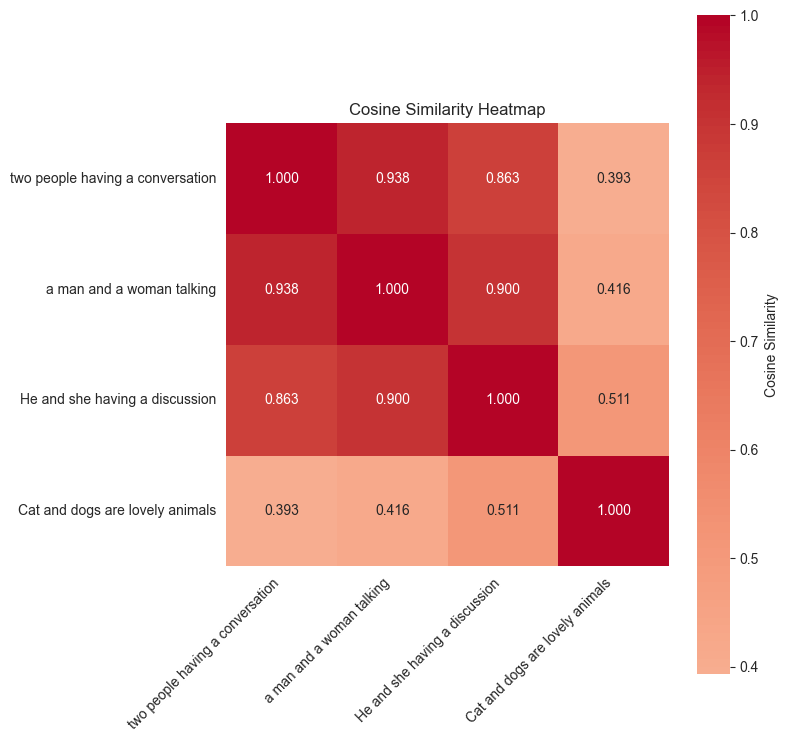
视频嵌入的挑战
视频带来了独特的挑战,因为它本质上是多模态的:
- 视觉信息:对象、场景、人物、动作和视觉美学
- 音频信息:语音、音乐、音效和环境噪音
- 文本信息:字幕、屏幕文字和转录的语音
传统的单向量方法将所有这些丰富的信息压缩成一个表示,通常会丢失重要的细微差别。这就是 TwelveLabs Marengo 的方法在有效应对这一挑战方面的独特性所在。
Twelvelabs Marengo:一个多模态嵌入模型
Marengo 3.0 模型生成多个专门的向量,每个向量捕获视频内容的不同方面。典型的电影或电视节目将视觉和听觉元素结合起来,创造统一的叙事体验。Marengo 的多向量架构为理解这种复杂的视频内容提供了显著优势。每个向量捕获一个特定的模态,避免了将多样化的数据类型压缩成单一表示而造成的信息丢失。这使得能够针对特定内容方面(仅视觉、仅音频或组合查询)进行灵活搜索。专门的向量在复杂的多模态场景中提供了卓越的准确性,同时为大型企业视频数据集保持了高效的可扩展性。
解决方案概述:Marengo 模型功能
在接下来的部分中,我们将通过代码示例演示 Marengo 嵌入技术的强大功能。这些示例说明了 Marengo 如何处理不同类型的内容并提供卓越的搜索准确性。完整的代码示例可以在这个 GitHub 仓库 中找到。
先决条件
在开始之前,请验证您是否具备以下条件:
- 具有适当权限的 AWS 账户。
- 对 Amazon Bedrock 的访问权限(已启用 TwelveLabs Marengo 模型)
- 创建 OpenSearch Serverless 集合和索引的权限
- 对向量数据库和嵌入的基本了解
示例视频
Netflix Open Content 是根据知识共享署名 4.0 国际许可提供的开源内容。我们将使用名为 Meridian 的视频之一来演示 Amazon Bedrock 上的 TwelveLabs Marengo 模型。

创建视频嵌入
Amazon Bedrock 使用异步 API 来生成 Marengo 视频嵌入。以下是一个 Python 代码片段,展示了调用 API 的示例,该 API 接收来自 S3 存储桶位置的视频。有关完整支持的功能,请参阅文档。
bedrock_client = boto3.client("bedrock-runtime") model_id = 'us.twelvelabs.marengo-embed-3-0-v1:0' video_s3_uri = "<s3 bucket location for the video>" # Replace by your s3 URI aws_account_id = "<the AWS account owner for the bucket>" # Replace by bucket owner ID s3_bucket_name = "<s3 bucket name>" # Replace by output S3 bucket name s3_output_prefix = "<output prefix>" # Replace by output prefix response = bedrock_client.start_async_invoke( modelId=model_id, modelInput={ "inputType": "video", "video": { "mediaSource": { "s3Location": { "uri": video_s3_uri, "bucketOwner": aws_account_id } } } }, outputDataConfig={ "s3OutputDataConfig": { "s3Uri": f's3://{s3_bucket_name}/{s3_output_prefix}' } } )上述示例从单个视频生成 280 个单独的嵌入——每个片段一个,从而实现精确的时间搜索和分析。来自视频的多向量输出的嵌入类型可能包含以下内容:
[ {'embedding': [0.053192138671875,...], 'embeddingOption': "visual", 'embeddingScope' : "clip", "startSec" : 0.0, "endSec" : 4.3 }, {'embedding': [0.053192138645645,...], 'embeddingOption': "transcription", 'embeddingScope' : "clip", "startSec" : 3.9, "endSec" : 6.5 }, {'embedding': [0.3235554er443524,...], 'embeddingOption': "audio", 'embeddingScope' : "clip", "startSec" : 4.9, "endSec" : 7.5 } ] - visual – 视频的视觉嵌入
- transcription – 转录文本的嵌入
- audio – 视频中音频的嵌入
在处理音频或视频内容时,您可以设置用于创建嵌入的每个片段的持续时间。默认情况下,视频片段会在自然场景变化(镜头边界)处自动分割。音频片段被分割成均匀的片段,尽可能接近 10 秒——例如,一个 50 秒的音频文件变成 5 个 10 秒的片段,而一个 16 秒的文件变成 2 个 8 秒的片段。默认情况下,单个 Marengo 视频嵌入 API 会生成视觉文本、视觉图像和音频嵌入。您也可以更改默认设置,仅输出特定的嵌入类型。使用以下代码片段通过 Amazon Bedrock API 为具有可配置选项的视频生成嵌入:
response = bedrock_client.start_async_invoke( modelId=model_id, modelInput={ "modelId": model_id, "modelInput": { "inputType": "video", "video": { "mediaSource": { "base64String": "base64-encoded string", // base64String OR s3Location, exactly one "s3Location": { "uri": "s3://amzn-s3-demo-bucket/video/clip.mp4", "bucketOwner": "123456789012" } }, "startSec": 0, "endSec": 6, "segmentation": { "method": "dynamic", // dynamic OR fixed, exactly one "dynamic": { "minDurationSec": 4 } "method": "fixed", "fixed": { "durationSec": 6 } }, "embeddingOption": [ "visual", "audio", "transcription" ], // optional, default=all "embeddingScope": [ "clip", "asset" ] // optional, one or both }, "inferenceId": "some inference id" } } )向量数据库:Amazon OpenSearch Serverless
在我们的示例中,我们将使用 Amazon OpenSearch Serverless 作为向量数据库,用于存储通过 Marengo 模型为给定视频生成的文本、图像、音频和视频嵌入。作为向量数据库,OpenSearch Serverless 允许您使用语义搜索快速查找相似内容,而无需担心管理服务器或基础设施。以下代码片段演示了如何创建 Amazon OpenSearch Serverless 集合:
aoss_client = boto3_session.client('opensearchserverless') try: collection = self.aoss_client.create_collection( name=collection_name, type='VECTORSEARCH' ) collection_id = collection['createCollectionDetail']['id'] collection_arn = collection['createCollectionDetail']['arn'] except self.aoss_client.exceptions.ConflictException: collection = self.aoss_client.batch_get_collection( names=[collection_name] )['collectionDetails'][0] pp.pprint(collection) collection_id = collection['id'] collection_arn = collection['arn']创建 OpenSearch Serverless 集合后,我们将创建一个包含属性(包括向量字段)的索引:
index_mapping = { "mappings": { "properties": { "video_id": {"type": "keyword"}, "segment_id": {"type": "integer"}, "start_time": {"type": "float"}, "end_time": {"type": "float"}, "embedding": { "type": "dense_vector", "dims": 1024, "index": True, "similarity": "cosine" }, "metadata": {"type": "object"} } } } credentials = boto3.Session().get_credentials() awsauth = AWSV4SignerAuth(credentials, region_name, 'aoss') oss_client = OpenSearch( hosts=[{'host': host, 'port': 443}], http_auth=self.awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection, timeout=300 ) response = oss_client.indices.create(index=index_name, body=index_mapping)索引 Marengo 嵌入
以下代码片段演示了如何将来自 Marengo 模型的嵌入输出摄取到 OpenSearch 索引中:
documents = [] for i, segment in enumerate(video_embeddings): document = { "embedding": segment["embedding"], "start_time": segment["startSec"], "end_time": segment["endSec"], "video_id": video_id, "segment_id": i, "embedding_option": segment.get("embeddingOption", "visual") } documents.append(document) # Bulk index documents bulk_data = [] for doc in documents: bulk_data.append({"index": {"_index": self.index_name}}) bulk_data.append(doc) # Convert to bulk format bulk_body = "\n".join(json.dumps(item) for item in bulk_data) + "\n" response = oss_client.bulk(body=bulk_body, index=self.index_name)跨模态语义搜索
利用 Marengo 的多向量设计,您可以搜索不同模态的内容,这是单向量模型无法实现的。通过为视觉、音频、运动和上下文元素创建独立但对齐的嵌入,您可以使用您选择的输入类型来搜索视频。例如,“爵士乐演奏”可以从一个文本查询返回演奏音乐的视频片段、爵士音频音轨和音乐厅场景。
以下示例展示了 Marengo 跨不同模态的卓越搜索能力:
文本搜索
这是一个代码片段,展示了使用文本的跨模态语义搜索功能:
text_query = "a person smoking in a room" modelInput={ "inputType": "text", "text": { "inputText": text_query } } response = self.bedrock_client.invoke_model( modelId="us.twelvelabs.marengo-embed-3-0-v1:0", body=json.dumps(modelInput)) result = json.loads(response["body"].read()) query_embedding = result["data"][0]["embedding"] # Search OpenSearch index search_body = { "query": { "knn": { "embedding": { "vector": query_embedding, "k": top_k } } }, "size": top_k, "_source": ["start_time", "end_time", "video_id", "segment_id"] } response = opensearch_client.search(index=self.index_name, body=search_body) print(f"\n✅ Found {len(response['hits']['hits'])} matching segments:") results = [] for hit in response['hits']['hits']: result = { "score": hit["_score"], "video_id": hit["_source"]["video_id"], "segment_id": hit["_source"]["segment_id"], "start_time": hit["_source"]["start_time"], "end_time": hit["_source"]["end_time"] } results.append(result)文本查询:“房间里有一个人吸烟”的最高搜索结果产生以下视频片段:

图像搜索
以下代码片段演示了给定图像的跨模态语义搜索功能:

s3_image_uri = f's3://{self.s3_bucket_name}/{self.s3_images_path}/{image_path_basename}' s3_output_prefix = f'{self.s3_embeddings_path}/{self.s3_images_path}/{uuid.uuid4()}' modelInput={ "inputType": "image", "image": { "mediaSource": { "s3Location": { "uri": s3_image_uri, "bucketOwner": self.aws_account_id } } } } response = self.bedrock_client.invoke_model( modelId=self.cris_model_id, body=json.dumps(modelInput), ) result = json.loads(response["body"].read()) ... query_embedding = result["data"][0]["embedding"] # Search OpenSearch index search_body = { "query": { "knn": { "embedding": { "vector": query_embedding, "k": top_k } } }, "size": top_k, "_source": ["start_time", "end_time", "video_id", "segment_id"] } response = opensearch_client.search(index=self.index_name, body=search_body) print(f"\n✅ Found {len(response['hits']['hits'])} matching segments:") results = [] for hit in response['hits']['hits']: result = { "score": hit["_score"], "video_id": hit["_source"]["video_id"], "segment_id": hit["_source"]["segment_id"], "start_time": hit["_source"]["start_time"], "end_time": hit["_source"]["end_time"] } results.append(result)上述图像的最高搜索结果产生了以下视频片段:

除了使用文本和图像对视频进行语义搜索之外,Marengo 模型还可以使用侧重于对话和语音的音频嵌入来搜索视频。音频搜索功能帮助用户根据特定的说话者、对话内容或口头主题查找视频。这创造了一个全面的视频搜索体验,结合了文本、图像和音频来实现视频理解。
结论
TwelveLabs Marengo 与 Amazon Bedrock 的结合,通过其多向量、多模态方法为视频理解开辟了令人兴奋的新可能性。在整篇文章中,我们探索了实际示例,例如具有时间精度的图像到视频搜索和详细的文本到视频匹配。仅通过一次 Bedrock API 调用,我们就将一个视频文件转换成了 336 个可搜索的片段,这些片段可以响应文本、视觉和音频查询。这些功能为自然语言内容发现、简化的媒体资产管理以及其他可以帮助组织在规模上更好地理解和利用其视频内容的应用程序创造了机会。
随着视频继续主导数字体验,像 Marengo 这样的模型为构建更智能的视频分析系统奠定了坚实的基础。请查看示例代码,探索多模态视频理解如何改变您的应用程序。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区