



📢 转载信息
原文作者:Raian Osman, Andy Orlosky, and Spencer Harrison
智能文档处理 (IDP) 正在改变组织处理非结构化文档数据的方式,实现从发票、合同和报告中自动提取有价值信息的能力。今天,我们将探讨如何以编程方式创建一个 IDP 解决方案,该方案利用 Strands SDK、Amazon Bedrock AgentCore、Amazon Bedrock 知识库 和 Bedrock 数据自动化 (BDA)。该解决方案通过一个 Jupyter 笔记本提供,使用户能够上传多模态业务文档,并利用 BDA 作为解析器来检索相关上下文,以增强到基础模型的提示词。在此用例中,我们的解决方案从美国教育部发布的《全国报告卡》中检索与公立学区相关的上下文。
Amazon Bedrock 数据自动化 (BDA) 可以作为独立功能使用,也可以在为检索增强生成 (RAG) 工作流程设置知识库时用作解析器。BDA 可用于从非结构化、多模态内容(如文档、图像、视频和音频)中生成有价值的见解。借助 BDA,您可以快速且经济高效地构建自动化的 IDP 和 RAG 工作流程。在构建 RAG 工作流程时,您可以使用 Amazon OpenSearch Service 来存储必要文档的向量嵌入。在这篇博文中,Bedrock AgentCore 通过工具利用 BDA 来为 IDP 解决方案执行多模态 RAG。
Amazon Bedrock AgentCore 是一项全托管服务,允许您构建和配置自主代理。开发人员可以使用流行的框架和包括来自 Amazon Bedrock、Anthropic、Google 和 OpenAI 在内的模型套件来构建和部署代理,而无需管理底层基础设施或编写自定义代码。
Strands Agents SDK 是一个复杂的开源工具包,它通过一种模型驱动的方法彻底改变了人工智能 (AI) 代理的开发。开发人员可以通过一个提示(定义代理行为)和工具列表来创建 Strands Agent。大型语言模型 (LLM) 会根据上下文和任务执行推理,自主决定最佳操作以及何时使用工具。此工作流程支持复杂的系统,最大限度地减少了编排多代理协作通常需要的代码。Strands SDK 用于创建代理并定义执行智能文档处理所需的工具。
请遵循以下先决条件和分步实现,在您自己的 AWS 环境中部署该解决方案。
先决条件
要跟随示例用例,请设置以下先决条件:
- 具有适当权限的 AWS 凭证
- 对 Github 的访问权限
- 本地安装 Git;有关说明,请参阅 入门 – 安装 Git
架构
该解决方案使用了以下 AWS 服务:
- Amazon S3 用于文档存储和上传功能
- Bedrock 知识库,用于将存储在 S3 中的对象转换为 RAG 就绪的工作流程
- Amazon OpenSearch 用于向量嵌入
- Amazon Bedrock AgentCore 用于 IDP 工作流程
- Strands Agent SDK 作为用于定义 IDP 工具的开源框架
- Bedrock Data Automation (BDA),用于从文档中提取结构化见解
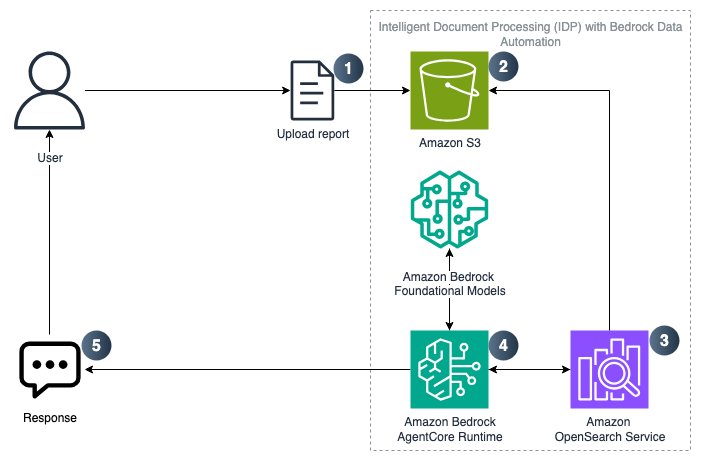
请遵循以下步骤开始操作:
- 将相关文档上传到 Amazon S3
- 创建 Amazon Bedrock 知识库,并使用 Amazon Bedrock Data Automation 解析 S3 数据源。
- 文档块存储为 Amazon OpenSearch 中的向量嵌入
- 部署在 Amazon Bedrock AgentCore Runtime 上的 Strands Agent 执行 RAG 以回答用户问题。
- 最终用户接收响应
配置 AWS CLI
使用以下命令使用您的 Amazon 账户和 AWS 区域的 AWS 凭证配置 AWS 命令行界面 (AWS CLI)。在开始之前,请检查 AWS Bedrock Data Automation 的区域可用性和定价:
aws configure在本地克隆并构建 GitHub 存储库
git clone https://github.com/aws-samples/sample-for-amazon-bda-agents
cd sample-for-amazon-bda-agents打开名为:
bedrock-data-automation-with-agents.ipynbBedrock 数据自动化与 AgentCore 笔记本说明:
该笔记本演示了如何使用 BDA 和 Amazon Bedrock AgentCore Runtime 创建 IDP 解决方案。我们将部署一个 Strands Agent(通过 AgentCore 部署),而不是传统的 Bedrock Agent,从而提供具有框架灵活性的企业级功能。下面概述了如何使用 BDA 作为解析器设置带有 Bedrock AgentCore 的 Bedrock 知识库。
步骤:
- 导入库并设置 AgentCore 功能
- 使用 BDA 创建 Amazon Bedrock 知识库
- 将学术报告数据集上传到 Amazon S3
- 使用 AgentCore Runtime 部署 Strands Agent
- 测试由 AgentCore 托管的代理
- 清理所有资源
安全注意事项
该实现使用了多项安全防护栏,例如:
- 安全文件上传处理
- 基于身份和访问管理 (IAM) 角色的访问控制
- 输入验证和错误处理
注意:此实现仅用于演示目的。在部署到生产环境之前,需要额外的安全控制、测试和架构审查。
优势和用例
此解决方案对于以下方面特别有价值:
- 自动化文档处理工作流程
- 大规模数据集的智能文档分析
- 基于文档内容的问答系统
- 多模态内容处理
结论
此解决方案演示了如何利用 Amazon Bedrock AgentCore 的功能来构建智能文档处理应用程序。通过构建支持 Amazon Bedrock Data Automation 的 Strands Agents,我们可以创建强大的应用程序,使用工具来理解和交互多模态文档内容。借助 Amazon Bedrock Data Automation,我们可以增强 RAG 体验,以处理更复杂的数据格式,包括富视觉文档、图像、音频和视频。
附加资源
欲了解更多信息,请访问 Amazon Bedrock。
服务用户指南:
- Amazon Bedrock 知识库用户指南
- Amazon Bedrock AgentCore 用户指南
- Strands Agents:开源 AI 代理 SDK
- Amazon Bedrock Data Automation 用户指南
相关示例:
关于作者
 Raian Osman 是 AWS 的一位技术客户经理,与北美地区的教育技术客户紧密合作。他已在 AWS 工作超过 3 年,最初的职位是解决方案架构师。Raian 与组织紧密合作,优化和保护 AWS 上的工作负载,同时探索生成式 AI 的创新用例。
Raian Osman 是 AWS 的一位技术客户经理,与北美地区的教育技术客户紧密合作。他已在 AWS 工作超过 3 年,最初的职位是解决方案架构师。Raian 与组织紧密合作,优化和保护 AWS 上的工作负载,同时探索生成式 AI 的创新用例。
 Andy Orlosky 是亚马逊云科技 (AWS) 的一位战略性方案架构师,常驻德克萨斯州奥斯汀。他加入 AWS 大约两年,但一直与公共部门的教育客户紧密合作。作为 AI/ML 技术现场社区的领导者,Andy 持续深入研究其客户需求,设计和扩展生成式 AI 解决方案。他拥有 7 项 AWS 认证,业余时间喜欢与家人共度时光、与朋友进行体育运动以及为他最喜欢的运动队加油。
Andy Orlosky 是亚马逊云科技 (AWS) 的一位战略性方案架构师,常驻德克萨斯州奥斯汀。他加入 AWS 大约两年,但一直与公共部门的教育客户紧密合作。作为 AI/ML 技术现场社区的领导者,Andy 持续深入研究其客户需求,设计和扩展生成式 AI 解决方案。他拥有 7 项 AWS 认证,业余时间喜欢与家人共度时光、与朋友进行体育运动以及为他最喜欢的运动队加油。
 Spencer Harrison 是亚马逊云科技 (AWS) 的一位合作伙伴解决方案架构师,他帮助公共部门组织利用云计算技术来专注于业务成果。他对利用技术改进流程和工作流充满热情。Spencer 的业余爱好包括阅读、匹克球和个人理财。
Spencer Harrison 是亚马逊云科技 (AWS) 的一位合作伙伴解决方案架构师,他帮助公共部门组织利用云计算技术来专注于业务成果。他对利用技术改进流程和工作流充满热情。Spencer 的业余爱好包括阅读、匹克球和个人理财。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区