



📢 转载信息
原文作者:Adewale Akinfaderin, Bharathi Srinivasan, and Nafi Diallo
在受监管的行业中,企业通常需要数学上的确定性,以确保每个 AI 回复都符合既定的策略和领域知识。受监管的行业无法使用仅测试 AI 输出的统计样本并对合规性做出概率性断言的传统质量保证方法。当我们在 2024 年 AWS re:Invent 上启动 Amazon Bedrock 护栏中的自动化推理检查(Automated Reasoning checks)预览版时,它提供了一种新颖的解决方案,通过将形式化验证技术应用于根据编码的业务规则和领域知识系统地验证 AI 输出,从而提供了解决方案。这些技术使验证输出具有透明性和可解释性。
自动化推理检查正被各行各业的工作流程中广泛使用。金融机构以数学上的确定性验证 AI 生成的投资建议是否符合监管要求。医疗组织确保患者指导与临床方案保持一致。制药公司确认营销声明有 FDA 批准的证据支持。公用事业公司在灾难期间验证应急响应协议,而法律部门则验证 AI 工具是否捕获了强制性的合同条款。
随着自动化推理的正式发布,我们增加了文档处理能力,并添加了如情景生成等新功能,该功能会自动创建演示策略规则如何实际应用的示例。借助增强的测试管理系统,领域专家可以构建、保存和自动执行全面的测试套件,以确保在模型和应用程序版本之间保持一致的策略执行。
在本篇分为两部分的技术深入探讨的第一部分中,我们将探讨 Amazon Bedrock 护栏中自动化推理检查的技术基础,并演示如何实现此功能,为生成式 AI 应用程序建立数学上严格的护栏。
在本文中,您将了解如何:
- 了解实现 AI 输出数学验证的形式化验证技术
- 从自然语言文档创建和精炼自动化推理策略
- 设计和实施有效的测试用例,以根据业务规则验证 AI 响应
- 通过注释应用策略精炼,以提高策略准确性
- 遵循 AWS 最佳实践,通过 Bedrock 护栏将自动化推理检查集成到您的 AI 应用程序工作流程中,以对生成的内容保持高度信心
通过遵循本实施指南,您可以系统地帮助在事实不准确和策略违规到达最终用户之前将其阻止,这对于需要在其 AI 系统中要求高保证和数学确定性的受监管行业的企业来说是一项关键能力。
自动化推理检查的核心能力
在本节中,我们将探讨自动化推理检查的能力,包括用于策略开发的控制台体验、文档处理架构、逻辑验证机制、测试管理框架和集成模式。了解这些核心组件将为您实施有效的生成式 AI 应用程序验证系统奠定基础。
控制台体验
Amazon Bedrock 自动化推理检查控制台将策略开发组织成逻辑部分,引导您完成创建、精炼和测试过程。该界面包括清晰的规则识别,具有唯一的 ID,并在规则中直接使用变量名,使复杂的策略结构易于理解和管理。
文档处理能力
文档处理支持多达 120K 个 Token(大约 100 页),因此您可以将大量知识库和复杂的策略文档编码到您的自动化推理策略中。组织可以纳入全面的策略手册、详细的程序文档和广泛的监管指南。利用此容量,您可以在单个策略中处理完整的文档。
验证能力
验证 API 包括模糊性检测,可识别需要澄清的陈述;用于无效发现的反例,演示验证失败的原因;以及具有有效和无效示例的可满足发现,以帮助理解边界条件。这些功能围绕验证结果提供上下文,以帮助您了解为什么特定的响应被标记以及如何改进它们。系统还可以表达其在自然语言和逻辑结构之间翻译的置信度,以便为特定用例设置适当的阈值。
迭代反馈和精炼过程
自动化推理检查提供详细的、可审计的发现结果,解释了为什么响应未能通过验证,从而支持迭代精炼过程,而不是简单地阻止不合规的内容。这些信息可以反馈给您的基础模型,使其能够根据具体反馈调整响应,直到它们符合策略规则为止。这种方法在受监管的行业中尤为有价值,在这些行业中,事实准确性和合规性必须经过数学验证而非估计。
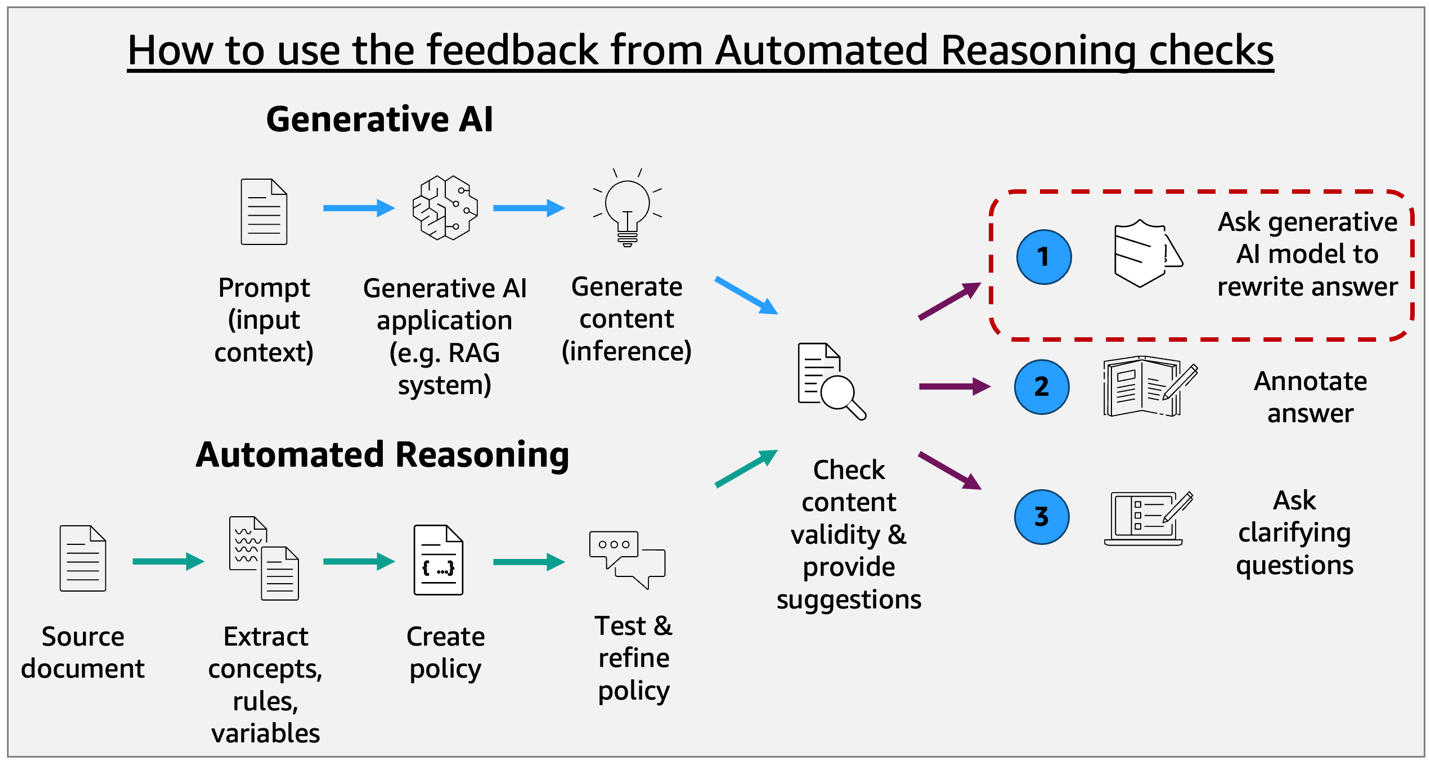
使用策略示例查找类型
考虑一个用于确定休息日的策略示例。在实施自动化推理检查时,策略由变量的架构(定义员工类型、服务年限和可用休假天数等概念)和一组逻辑规则(建立这些变量之间关系,如不同类型休假的资格条件)组成。在验证过程中,系统使用此架构和规则结构来评估基础模型响应是否符合您定义的策略约束。
我们希望验证用户向基础模型(FM)支持的应用程序提出的以下输入以及生成的输出。
Input:
"如果今天是公共假日,周四算不算休息日?" Output:
"是的,如果今天是公共假日,周四将是休息日,因为所有公共假日都被视为休息日,无论星期几。"前提是从中得出结论的陈述,而声明是真理的断言。在此示例中,推断的前提是 day 等于 “Thursday” 且 is_public_holiday 为 true,并且做出 is_day_off 为 true 的声明。
该推理遵循自动化推理策略:
休息日策略:
- 所有周末(周六和周日)都是休息日
- 所有公共假日都是休息日
- 如果某天是周末或公共假日,则该天被视为休息日随着通用可用性(General Availability)的发布,自动化推理检查现在生成七种不同的发现类型,为 FM 生成响应的验证过程提供精确的见解:
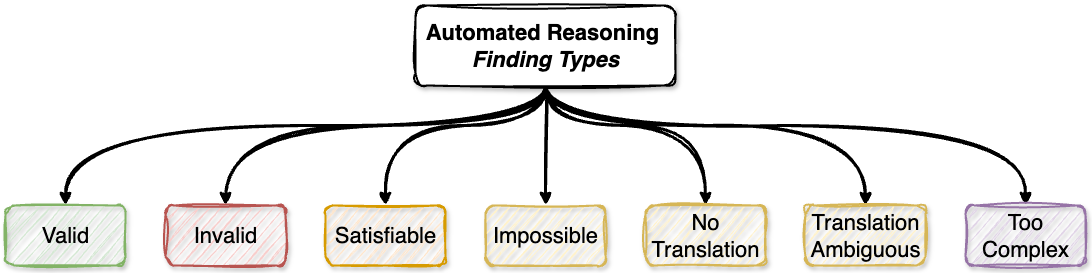
VALID(有效):确认 输入和输出完全符合策略规则,提供了置信度,即生成响应中的信息根据您定义的策略是正确的。声明是从前提和 AR 策略中推断出来的,并被验证为真实,并且没有与这些声明相矛盾的替代答案。
Input:
今天是周日,我今天休息吗? Output:
是的,周日是周末,您今天休息。 Premises:
day: Sunday
is_weekend: true Claim:
is_day_off: true Explanation:
根据分配的变量和周末是休息日的策略规则,唯一可能的答案是休息日。SATISFIABLE(可满足):识别出输入和输出可能为真或为假,具体取决于特定假设。这些发现可帮助您了解响应仅在某些条件下有效的边界条件,以便您可以决定这些假设在您的环境中是否合理。如果所需的假设为假,则可能存在与前提一致的替代声明。
Input:
今天是星期二,我休息吗? Output:
是 Premises:
day: Tuesday Claim:
is_day_off: true Explanation: 如果我们假设 is_public_holiday=true,这是正确的,但如果我们假设 is_public_holiday=false,答案将不正确,因为星期二不是周末。INVALID(无效):识别出输入和输出存在策略不准确或事实错误,并通过明确演示验证失败原因的反例进行了增强。声明并非由前提和 AR 策略所暗示,并且存在与前提和 AR 策略一致的不同声明。
Input:
今天是周日,我休息吗? Output:
不,您今天不休息。 Premises:
day: Sunday Claim:
is_day_off: false Explanation:
这是无效的,因为策略规定周末是休息日。正确的声明应该是 is_day_off = true,因为周日是周末。IMPOSSIBLE(不可能):指示由于前提与 AR 策略冲突或策略包含内部矛盾,因此无法生成任何有效的声明。当策略中定义的约束导致逻辑上的不可能情况时,会出现此发现。
Input: 今天是周日但不是周末,我休息吗? Output:
是 Premises:
day: Sunday
is_weekend: false Claim:
is_day_off: true Explanation: 周日总是周末,因此前提包含矛盾。鉴于这些矛盾的前提,不存在有效的声明。NO_TRANSLATIONS(无翻译):当输入和输出不包含可翻译为 AR 策略评估相关数据的任何信息时发生。这通常发生在文本完全与策略域无关或不包含任何可操作信息时。
Input: 平均猫有几条腿? Output:
少于 4 Explanation:
AR 策略是关于休息日的,因此没有关于猫的内容的相关翻译。输入与策略域无关。TRANSLATION_AMBIGUOUS(翻译模糊):识别出输入和输出中存在模糊性,阻止了向逻辑结构的明确翻译。此发现表明可能需要额外的上下文或后续问题才能继续验证。
Input: 我赢了!今天是“赢日”,我能休息吗? Output:
是的,您可以休息! Explanation: "Winsday" 在 AR 策略中不是公认的一天,造成了模糊性。如果没有关于所引用哪一天的澄清,自动化推理无法继续。TOO_COMPLEX(过于复杂):指示输入和输出包含过多信息,无法在延迟限制内处理。当输入极其庞大或复杂,超出系统当前处理能力时,会出现此发现。
Input:
您能告诉我未来 3 年所有 50 个州加上领地的休息日是哪几天吗,同时考虑联邦、州和地方假日?请包括浮动假日和特殊纪念日的例外情况。 Output:
我分析了所有 50 个州的假日日历。在阿拉巴马州,休息日包括…… Explanation: 此用例包含的变量和条件太多,AR 检查无法在保持准确性和响应时间要求的同时进行处理。情景生成
您现在可以直接从策略生成情景,这会创建符合策略规则的测试样本,帮助识别边缘情况,并支持验证策略的业务逻辑实现。利用此功能,策略作者可以在部署前看到规则在实践中如何运作的具体示例,减少了广泛手动测试的需求。情景生成还突出了可能从检查单个规则中不明显的潜在冲突或策略覆盖范围的差距。
测试管理系统
一个新的测试管理系统允许您保存和注释策略测试、构建测试库以实现一致验证、自动执行测试以验证策略更改,以及跨策略版本维护质量保证。该系统包括版本控制功能,可以跟踪策略迭代中的测试结果,从而更轻松地识别更改是否可能产生意外后果。现在您也可以导出测试结果,以便与现有质量保证工作流程和文档流程集成。
直接护栏集成带来的扩展选项
自动化推理检查现已与 Amazon Bedrock API 集成,可以在复杂的交互过程中根据既定策略验证 AI 生成的响应。此集成扩展到 Converse 和 RetrieveAndGenerate 操作,允许跨不同交互模式执行策略强制。组织可以根据其领域要求配置验证置信度阈值,在受监管行业中可以选择更严格的执行,或在探索性环境中选择更灵活的应用。
解决方案——AI 驱动的医院再入院风险评估系统
既然我们已经解释了自动化推理检查的能力,让我们通过考虑一个 AI 驱动的医院再入院风险评估系统的用例来研究一个解决方案。该 AI 系统通过分析电子健康记录中的患者数据,将患者分类为风险类别(低、中、高),并根据 CDC 式指南推荐个性化的干预计划,从而实现医院再入院风险评估的自动化。该 AI 系统的目标是通过支持对高风险患者的早期识别和实施有针对性的干预措施,来降低 30 天的医院再入院率。此应用程序是自动化推理检查的理想候选者,因为医疗服务提供者优先考虑可验证的准确性和可解释的建议,这些建议可以经过数学证明符合医疗指南,从而支持临床决策制定,并满足医疗保健环境中常见的严格审计要求。
注意:引用的策略文件是为演示目的创建的示例,不应用于实际医疗指南或临床决策制定。
先决条件
要使用 Amazon Bedrock 中的自动化推理检查,请验证您已满足以下先决条件:
- 一个活动的 AWS 账户
- 确认自动化推理检查可用的 AWS 区域
- 用于创建、测试和调用自动化推理策略的适当 IAM 权限(注意:IAM 策略应是细粒度的,并使用适当的 ARN 模式限制到必要的资源,以用于生产环境):
{ "Sid": "OperateAutomatedReasoningChecks", "Effect": "Allow", "Action": [ "bedrock:CancelAutomatedReasoningPolicyBuildWorkflow", "bedrock:CreateAutomatedReasoningPolicy", "bedrock:CreateAutomatedReasoningPolicyTestCase", "bedrock:CreateAutomatedReasoningPolicyVersion", "bedrock:CreateGuardrail", "bedrock:DeleteAutomatedReasoningPolicy", "bedrock:DeleteAutomatedReasoningPolicyBuildWorkflow", "bedrock:DeleteAutomatedReasoningPolicyTestCase", "bedrock:ExportAutomatedReasoningPolicyVersion", "bedrock:GetAutomatedReasoningPolicy", "bedrock:GetAutomatedReasoningPolicyAnnotations", "bedrock:GetAutomatedReasoningPolicyBuildWorkflow", "bedrock:GetAutomatedReasoningPolicyBuildWorkflowResultAssets", "bedrock:GetAutomatedReasoningPolicyNextScenario", "bedrock:GetAutomatedReasoningPolicyTestCase", "bedrock:GetAutomatedReasoningPolicyTestResult", "bedrock:InvokeAutomatedReasoningPolicy", "bedrock:ListAutomatedReasoningPolicies", "bedrock:ListAutomatedReasoningPolicyBuildWorkflows", "bedrock:ListAutomatedReasoningPolicyTestCases", "bedrock:ListAutomatedReasoningPolicyTestResults", "bedrock:StartAutomatedReasoningPolicyBuildWorkflow", "bedrock:StartAutomatedReasoningPolicyTestWorkflow", "bedrock:UpdateAutomatedReasoningPolicy", "bedrock:UpdateAutomatedReasoningPolicyAnnotations", "bedrock:UpdateAutomatedReasoningPolicyTestCase", "bedrock:UpdateGuardrail" ], "Resource": [ "arn:aws:bedrock:${aws:region}:${aws:accountId}:automated-reasoning-policy/*", "arn:aws:bedrock:${aws:region}:${aws:accountId}:guardrail/*" ] }- 关键服务限制:在实施自动化推理检查时,请注意服务限制。
- 使用自动化推理检查时,您需要根据处理的文本量付费。有关更多信息,请参阅 Amazon Bedrock 定价。有关更多信息,请参阅 Amazon Bedrock 定价。
用例和策略数据集概述
本示例中使用的完整策略文档可以从 自动化推理 GitHub 存储库中访问。 为了验证自动化推理检查的结果,了解策略会很有帮助。此外,精炼由自动化推理创建的策略是实现超过 99% 健全性的关键。
让我们回顾一下我们在本文中使用的示例医疗策略的主要细节。当我们开始验证结果时,对照源文档进行验证将很有帮助。
- 风险评估和分层: 医疗机构必须根据人口统计、临床、利用率、实验室和社会因素实施标准化的风险评分系统,将患者分为低(0-3 分)、中等(4-7 分)或高风险(8+ 分)类别。
- 强制性干预措施: 每个风险级别都需要特定的干预措施,高风险级别包括较低级别的干预措施以及额外的措施,而某些情况会触发自动高风险分类,无论得分如何。
- 质量指标和合规性: 机构必须实现特定的完成率,包括入院后 24 小时内 95% 以上的风险评估,以及出院前 100% 完成,高风险患者需要有文件记录的出院计划。
- 临床监督: 尽管评分系统是标准化的,但主治医师在经过出院计划协调员的适当记录和批准后保留否决权。
使用 Amazon Bedrock 控制台创建和测试自动化推理检查的策略
第一步是将您的知识——在本例中是示例医疗策略——编码到自动化推理策略中。完成以下步骤以创建自动化推理策略:
- 在 Amazon Bedrock 控制台上,在导航窗格的 Build 下选择 Automated Reasoning。
- 选择 Create policy。
- 提供策略名称和策略描述。

- 添加自动化推理将从中生成策略的源内容。您可以上传文档(pdf、txt)或输入文本作为摄取方法。

- 包含您正在创建的自动化推理策略意图的描述。意图是可选的,但为将基于自然语言的文档转换为可用于数学验证的一组规则的大型语言模型提供了有价值的信息。对于示例策略,您可以使用以下意图:
This logical policy validates claims about the clinical practice guideline providing evidence-based recommendations for healthcare facilities to systematically assess and mitigate hospital readmission risk through a standardized risk scoring system, risk-stratified interventions, and quality assurance measures, with the goal of reducing 30-day readmissions by 15-23% across participating healthcare systems. Following is an example patient profile and the corresponding classification. <Patient Profile>Age: 82 years Length of stay: 10 days Has heart failure One admission within last 30 days Lives alone without caregiver <Classification> High Risk
- 策略创建后,我们可以检查定义,查看已创建哪些规则、变量和类型,以将文档中的知识表示为逻辑。

您看到的规则、变量和类型的数量可能与本示例中显示的不同。这是由于所提供文档的处理是非确定性的。为解决此问题,建议的指导是在将生成的信息用于其他系统之前,对生成的信息进行人工干预审查。
探索自动化推理检查的定义
策略文档的变量(Variable)是容纳特定类型信息(如整数、实数或布尔值)的命名容器,代表策略中的一个不同概念或度量。变量充当规则的构建块,可用于跟踪、度量和评估策略要求。从下面的图像中,我们可以看到诸如 admissionsWithin30Days(跟踪先前住院的整数变量)、ageRiskPoints(存储基于年龄的风险分数的整数变量)和 conductingMonthlyHighRiskReview(指示是否正在执行月度审查的布尔变量)之类的示例。每个变量都有其目的和所代表的特定策略概念的清晰描述,使得可以在规则中使用这些变量来强制执行策略要求和度量合规性。问题还突出显示某些变量未被使用。验证这些变量代表哪些概念并识别是否缺少规则尤为重要。
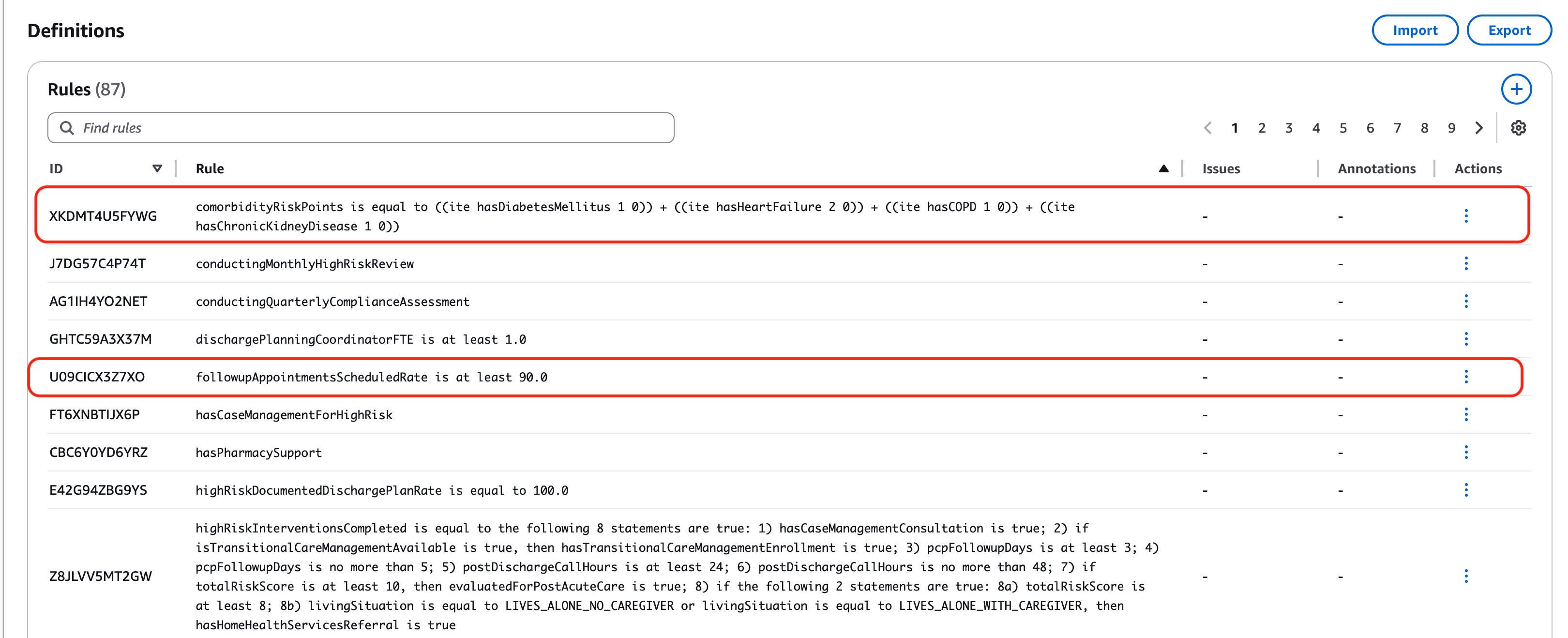
在Definitions(定义)中,我们看到了“Rules”(规则)、“Variables”(变量)和“Types”(类型)。规则是自动化推理从源文档中提取的明确的逻辑陈述。考虑已创建的这个简单规则: followupAppointmentsScheduledRate is at least 90.0 – 此规则来自 Section III A Process Measures,其中指出医疗机构应监控各种过程指标,要求出院前安排的后续门诊预约应达到 90% 或更高。
让我们看一个更复杂的规则:
comorbidityRiskPoints is equal to(ite hasDiabetesMellitus 1 0) + (ite hasHeartFailure 2 0) + (ite hasCOPD 1 0) + (ite hasChronicKidneyDisease 1 0)Where “ite” is “If then else”此规则根据策略文档中指定的现有医疗状况(合并症)计算患者的风险分数。在评估患者时,系统会检查四个特定条件:任何类型的糖尿病(值 1 分)、任何分类的心力衰竭(值 2 分)、慢性阻塞性肺病(值 1 分)和慢性肾病 3-5 期(值 1 分)。该规则通过使用布尔逻辑将这些分数相加——这意味着它将每个条件(表示为 true=1 或 false=0)乘以其分配的点值,然后将所有值相加以生成总的合并症风险得分。例如,如果患者同时患有心力衰竭和糖尿病,他们将获得 3 总分(心力衰竭 2 分 + 糖尿病 1 分)。此合并症分数随后成为确定患者总体再入院风险类别的更大风险评估框架的一部分。

定义还包括自定义变量类型。自定义变量类型,也称为枚举(ENUM),是定义特定策略概念允许值的固定集合的专门数据结构。这些自定义类型通过将值限制为符合策略要求的预定义选项,来保持数据收集和规则执行的一致性和准确性。在示例策略中,我们可以看到识别出四种自定义变量类型:
AdmissionType:这定义了可能的住院类型(MEDICAL、SURGICAL、MIXED_MEDICAL_SURGICAL、PSYCHIATRIC),这些类型决定了患者是否符合再入院风险评估方案的资格。HealthcareFacilityType:这指定了再入院风险评估方案可能适用的医疗机构类型(ACUTE_CARE_HOSPITAL_25PLUS、CRITICAL_ACCESS_HOSPITAL)…… [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区