



📢 转载信息
原文作者:Archie Cowan
AWS AppSync 事件可以帮助您创建更安全、可扩展的 Websocket API。除了向数百万订阅者广播实时事件外,它还支持 AI 网关的一个关键用户体验要求:将来自您所选生成式 AI 模型的事件低延迟地传播给单个用户。
在本文中,我们将讨论如何使用 AppSync 事件作为功能强大的无服务器 AI 网关架构的基础。我们将探讨它如何与 AWS 服务集成,以全面覆盖 AI 网关架构提供的能力。最后,我们将提供您可以在自己的账户中启动并开始构建的示例代码,助您踏上构建之旅。
AI 网关概述
AI 网关是一种架构中间件模式,有助于增强大型语言模型 (LLM) 的可用性、安全性和可观测性。它服务于组织内不同角色的需求。例如,用户需要低延迟和愉悦的体验。开发人员需要灵活且可扩展的架构。安全人员需要治理来保护信息和可用性。系统工程师需要监控和可观测性解决方案来帮助他们支持用户体验。产品经理需要有关其产品对用户性能如何的信息。预算管理者需要成本控制。组织中这些不同人员的需求是托管生成式 AI 应用程序的重要考虑因素。
解决方案概述
我们在本文中分享的解决方案提供以下功能:
- 身份识别 – 能够从内置用户目录、企业目录以及 Amazon、Google 和 Facebook 等消费者身份提供商处对用户进行身份验证和授权
- API – 为用户和应用程序提供对您的生成式 AI 应用程序的低延迟访问
- 授权 – 确定用户在应用程序中可以访问哪些资源
- 速率限制和计量 – 缓解机器人流量、阻止访问并管理模型消耗以控制成本
- 多样化的模型访问 – 提供对领先的基础模型 (FM)、智能体和安全措施的访问,以确保用户安全
- 日志记录 – 观察、故障排除和分析应用程序行为
- 分析 – 从日志中提取价值以构建、发现和共享有意义的见解
- 监控 – 跟踪关键数据点,帮助员工快速响应事件
- 缓存 – 通过检测对模型的常见查询并返回预定响应来降低成本
在接下来的章节中,我们将深入探讨核心架构,并探讨如何将这些功能构建到解决方案中。
身份和 API
下图展示了使用 AppSync 事件 API 作为 AI 助手应用程序与 Amazon Bedrock 中的 LLM 之间的接口的架构,其中使用了 AWS Lambda。
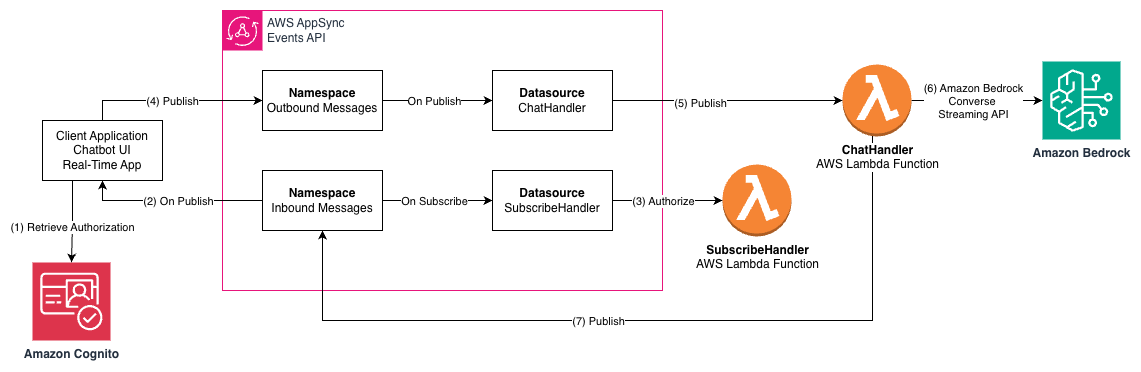
工作流程包括以下步骤:
- 客户端应用程序使用 Amazon Cognito 检索用户身份并授权访问 API。
- 客户端应用程序订阅 AppSync 事件通道,它将从此通道接收 LLM 流式响应等事件。
- 附加到“出站消息”命名空间(Outbound Messages namespace)的
SubscribeHandlerLambda 函数会验证此用户是否有权访问该通道。 - 客户端应用程序向“入站消息”通道(Inbound Message channel)发布消息,例如向 LLM 提出的问题。
ChatHandlerLambda 函数接收消息并验证用户是否有权在该通道上发布消息。ChatHandler函数调用 Amazon Bedrock ConverseStream API,并等待 Converse API 的响应流发出响应事件。ChatHandler函数将来自 Converse API 的响应消息中继到当前用户的“出站消息”通道,然后将事件传递给正在等待消息的 WebSocket。
AppSync 事件的命名空间和通道是 AI 网关通信架构的构建块。在示例中,命名空间用于将不同的行为附加到我们的入站和出站消息上。每个命名空间可以与每个命名空间具有不同的发布和订阅集成。此外,每个命名空间都划分为通道。我们的通道结构设计为每个用户提供一个私有的入站和出站通道,作为与服务器端的一对一通信:
Inbound-Messages / ${sub}Outbound-Messages / ${sub}
subject,即 sub 属性,会作为 Amazon Cognito 提供的上下文到达我们的 Lambda 函数中。它是每个用户池中一个不可更改的唯一用户标识符。这使其非常适合用于我们的通道名称的片段,并且在授权方面特别有用。
授权
身份是使用 Amazon Cognito 建立的,但我们仍然需要实施授权。在我们示例中,用户与 AI 助手之间的一对一通信应该是私密的——我们不希望知道另一个用户 sub 属性的用户能够订阅或发布到另一个用户的入站或出站通道。
这就是我们在通道命名方案中使用 sub 的原因。这使得附加到命名空间作为数据源的 Lambda 函数能够验证用户是否有权发布和订阅。
以下代码示例是我们的 SubscribeHandler Lambda 函数:
def lambda_handler(event, context):
"""
Lambda function that checks if the first channel segment matches the user's sub.
Returns None if it matches or an error message otherwise.
""" # Extract segments and sub from the event
segments = event.get("info", {}).get("channel", {}).get("segments")
sub = event.get("identity", {}).get("sub", None) # Check if segments exist and the first segment matches the user's sub
if not segments:
logger.error("No segments found in event")
return "No segments found in channel path" if sub != segments[1]:
logger.warning(
f"Unauhotirzed: Sub '{sub}' did not match path segment '{segments[1]}'")
return "Unauthorized" logger.info(f"Sub '{sub}' matched path segment '{segments[1]}'") return None该函数的工作流程包括以下步骤:
- 通道的名称作为事件传入。
- 用户的 subject 字段
sub是上下文的一部分。 - 如果通道名称和用户身份不匹配,则不会授权订阅并返回错误消息。
- 返回
None表示没有错误,并且订阅已获得授权。
ChatHandler Lambda 函数使用相同的逻辑来确保用户只能授权向其自己的入站通道发布消息。通道作为事件传入,上下文携带用户身份。
尽管我们的示例很简单,但它演示了如何使用 Lambda 函数使用复杂的授权规则来授权访问 AppSync 事件中的通道。我们已经涵盖了对个人入站和出站通道的访问控制。许多围绕访问 LLM 的业务模型都涉及控制个人在特定时间段内可以使用的 token 数量。我们在下一节中讨论此功能。
速率限制和计量
了解和控制 AI 网关用户消耗的 token 数量对许多客户都很重要。输入和输出 token 是在 Amazon Bedrock 中进行基于文本的 LLM 的主要定价机制。在我们的示例中,我们使用 Amazon Bedrock Converse API 来访问 LLM。Converse API 提供了一个一致的接口,可用于支持消息的模型。您可以编写一次代码并将其用于不同的模型。
一致接口的一部分是流元数据事件。此事件在每个流结束时发出,并提供流消耗的 token 数量。以下是示例 JSON 结构:
{
"metadata": {
"usage": {
"inputTokens": 1062,
"outputTokens": 512,
"totalTokens": 1574
},
"metrics": {
"latencyMs": 4133
}
}
}我们有输入 token、输出 token、总 token 和延迟指标。为了用这些数据创建控制,我们首先考虑我们想要实施的限制类型。一种方法是每月重置一次的月度 token 限制——一个静态窗口。另一种是基于 10 分钟间隔的滚动窗口的每日限制。当用户超过其月度限制时,他们必须等到下个月。当用户超过其每日滚动窗口限制后,他们必须等待 10 分钟才能获得更多可用 token。
我们需要一种方法来保持原子计数器,以跟踪 token 消耗,并使用用户的 sub 快速实时访问这些计数器,并在它们变得不相关时删除旧计数器。
Amazon DynamoDB 是一种无服务器、完全托管、分布式 NoSQL 数据库,可在多种规模下实现个位数毫秒性能。使用 DynamoDB,我们可以保留原子计数器,通过 sub 键访问这些计数器,并使用其生存时间功能来淘汰旧数据。下图显示了早期架构的一个子集,其中现在包含一个 DynamoDB 表来跟踪 token 使用情况。
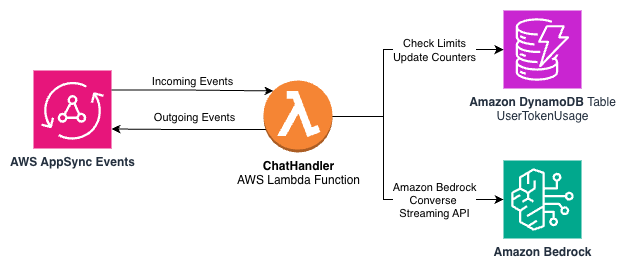
我们可以使用一个具有以下分区键和排序键的 DynamoDB 表:
- 分区键 –
user_id(String),用户的唯一标识符 - 排序键 –
period_id(String),一个复合键,用于标识时间段
user_id 将接收 Amazon Cognito 提供的 JWT 中的 sub 属性。period_id 将包含按字母顺序排序的字符串,指示计数器所属的时间段和时间范围。以下是一些示例排序键:
10min:2025-08-05:16:40
10min:2025-08-05:16:50
monthly:2025-0810min 或 monthly 指示计数器类型。时间戳设置为最近的 10 分钟窗口(例如,(minute // 10) * 10)。
对于每个记录,我们保留以下属性:
input_tokens– 此 10 分钟窗口中使用的输入 token 计数器output_tokens– 此 10 分钟窗口中使用的输出 token 计数器timestamp– 记录创建或最后更新的 Unix 时间戳ttl– 生存时间值(Unix 时间戳),设置为自创建起的 24 小时
两个 token 列使用 DynamoDB 的原子 ADD 操作,在每次收到来自 Amazon Bedrock Converse API 的元数据事件时递增。ttl 和 timestamp 列会被更新,以指示记录何时从表中自动删除。
当用户发送消息时,我们检查他们是否超过了每日或每月的限制。
要计算每日使用情况,meter.py 模块完成以下步骤:
- 计算 24 小时窗口的开始和结束键。
- 查询分区键为
user_id且排序键在开始键和结束键之间的记录。 - 对匹配记录的
input_tokens和output_tokens值求和。 - 将总和与每日限制进行比较。
请参阅以下示例代码:
KeyConditionExpression: "user_id = :uid AND period_id BETWEEN :start AND :end"
ExpressionAttributeValues: {
":uid": {"S": "user123"},
":start": {"S": "10min:2025-08-04:15:30"},
":end": {"S": "10min:2025-08-05:15:30"}
}此范围查询利用了自然排序的键来有效检索过去 24 小时内的记录,而无需在应用程序代码中进行过滤。静态窗口上的月度使用情况计算要简单得多。要检查月度使用情况,系统完成以下步骤:
- 获取分区键为
user_id且排序键为当前月份monthly:YYYY-MM的特定记录。 - 将
input_tokens和output_tokens值与月度限制进行比较。
请参阅以下代码:
Key: {
"user_id": {"S": "user123"},
"period_id": {"S": "monthly:2025-08"}
}通过一个额外的 Python 模块和 DynamoDB,我们有了一个适用于静态窗口和滚动窗口的计量和速率限制解决方案。
多样化的模型访问
我们的示例代码使用了 Amazon Bedrock Converse API。并非所有模型都包含在示例代码中,但包含了许多模型供您快速探索可能性。该领域的创新不止于 AWS 上的模型。在各个抽象级别上,都有许多方法可以开发生成式 AI 解决方案。您可以根据最适合您用例的层进行构建。
Swami Sivasubramanian 最近撰文介绍了 AWS 如何帮助客户规模化交付生产就绪的 AI 智能体。他讨论了开源 AI 智能体 SDK Strands Agents,以及 Amazon Bedrock AgentCore,这是一套全面的企业级服务,可使用托管在 Amazon Bedrock 或其他地方的框架和模型,帮助开发人员快速、更安全地大规模部署和操作 AI 智能体。
要了解有关 AI 智能体架构的更多信息,请参阅Strands Agents SDK:深入探究智能体架构和可观测性。这篇文章讨论了 Strands Agents SDK 及其核心功能、它如何与 AWS 环境集成以实现更安全、可扩展的部署,以及它如何为生产使用提供丰富的可观测性。它还提供了实际用例和分步示例。
日志记录
我们的许多 AI 网关利益相关者都对日志感兴趣。开发人员希望了解其应用程序的功能。系统工程师需要了解运营方面的考虑因素,例如跟踪可用性和容量规划。企业主希望获得分析和趋势,以便他们可以做出更好的决策。
使用 Amazon CloudWatch Logs,您可以将不同系统、应用程序和所使用的 AWS 服务的日志集中到一个高度可扩展的服务中。然后,您可以无缝查看它们、搜索特定错误代码或模式、根据特定字段进行过滤,或安全地存档以供将来分析。CloudWatch Logs 使得无论日志源如何,都可以将日志视为按时间排序的单一、一致的事件流。
在示例 AI 网关架构中,CloudWatch Logs 在多个级别集成,以提供全面的可见性。下图描绘了示例应用程序中 AppSync 事件、Lambda 和 CloudWatch Logs 之间的集成点。
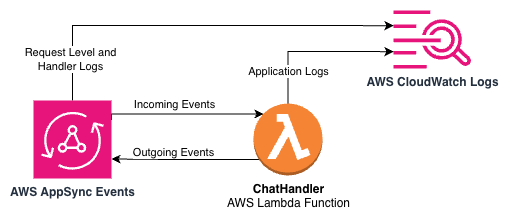
AppSync 事件 API 日志记录
我们的 AppSync 事件 API 配置了 ERROR 级别的日志记录,以捕获 API 级别的问题。此配置有助于识别 API 请求、身份验证失败和其他关键 API 级别问题。
日志记录配置是在基础设施部署期间应用的:
this.api = new appsync.EventApi(this, "Api", {
// ... other configuration ...
logConfig: {
excludeVerboseContent: true,
fieldLogLevel: appsync.AppSyncFieldLogLevel.ERROR,
retention: logs.RetentionDays.ONE_WEEK,
},
});这提供了对 API 操作的可见性。
Lambda 函数结构化日志记录
Lambda 函数使用 AWS Lambda Powertools 进行结构化日志记录。ChatHandler Lambda 函数实现了一个 MessageTracker 类,为每次对话提供上下文:
logger = Logger(service="eventhandlers")
class MessageTracker:
"""
Tracks message state during processing to provide enhanced logging.
Handles event type detection and processing internally.
""" def __init__(self, user_id, conversation_id, user_message, model_id):
self.user_id = user_id
self.conversation_id = conversation_id
self.user_message = user_message
self.assistant_response = ""
self.input_tokens = 0
self.output_tokens = 0
self.model_id = model_id
# ...关键日志信息包括:
- 用户标识符
- 用于请求跟踪的会话标识符
- 模型标识符,用于跟踪正在使用的 AI 模型
- Token 消耗指标(输入和输出计数)
- 消息预览
- 用于时间序列分析的详细时间戳
每个 Lambda 函数都设置了一个相关性 ID 用于请求跟踪,从而可以轻松地在系统中跟踪单个请求:
# Set correlation ID for request tracing
logger.set_correlation_id(context.aws_request_id)操作洞察
CloudWatch Logs Insights 允许跨日志数据执行类似 SQL 的查询,帮助您执行以下操作:
- 按模型或用户跟踪 token 使用模式
- 监控响应时间和识别性能瓶颈
- 检测错误模式并排除故障
- 基于日志数据创建自定义指标和警报
通过在整个示例 AI 网关架构中实施全面的日志记录,我们提供了有效故障排除、性能优化和操作监控所需的可见性。此日志记录基础架构为操作监控和我们在下一节中讨论的分析功能奠定了基础。
分析
CloudWatch Logs 提供操作可见性,但要从日志中提取商业智能,AWS 提供了许多分析服务。使用我们的示例 AI 网关架构,您可以使用这些服务来转换来自 AI 网关的数据,而无需专用基础设施或复杂的数据管道。
下图展示了 Lambda 函数、Amazon Data Firehose、Amazon Simple Storage Service (Amazon S3)、AWS Glue 数据目录和 Amazon Athena 之间的数据流。
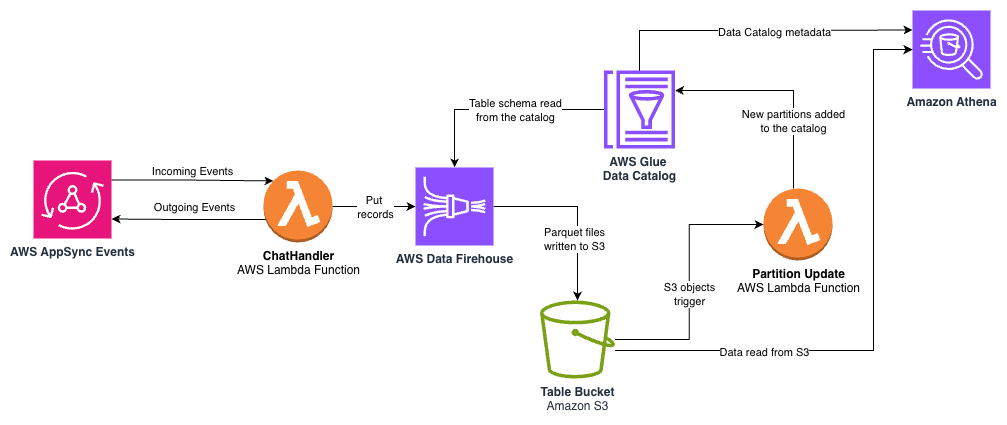
关键组件包括:
- Data Firehose –
ChatHandlerLambda 函数在每个完成的用户响应结束时将结构化日志数据流式传输到 Firehose 交付流。Data Firehose 提供了一个完全托管的服务,可根据您的数据吞吐量自动扩展,从而无需预置或管理基础设施。以下代码说明了将ChatHandlerLambda 函数与交付流集成的 API 调用:
# From messages.py
firehose_stream = os.environ.get("FIREHOSE_DELIVERY_STREAM")
if firehose_stream:
try:
firehose.put_record(
DeliveryStreamName=firehose_stream,
Record={"Data": json.dumps(log_data) + "\n"},
)
logger.debug(f"Successfully sent data to Firehose stream: {firehose_stream}")
except Exception as e:
logger.error(f"Failed to send data to Firehose: {str(e)}")- Amazon S3 with Parquet format – Firehose 在将 JSON 日志数据存储到 Amazon S3 之前,自动将其转换为列式 Parquet 格式。与原始 JSON 日志相比,Parquet 提高了查询性能并降低了存储成本。数据按年、月和日分区,从而可以高效地查询特定时间范围,同时最大限度地减少查询期间扫描的数据量。
- AWS Glue 数据目录 – 在 AWS Cloud Development Kit (AWS CDK) 应用程序中创建了一个 AWS Glue 数据库和表,用于定义分析数据的架构,包括
user_id、conversation_id、model_id、token 计数和时间戳。当 Data Firehose 存储新的 S3 对象时,会向表中添加表分区。 - Athena for SQL-based analysis – 使用数据目录中的表,业务分析师可以通过 Athena 使用熟悉的 SQL 来提取见解。Athena 是无服务器的,并且根据扫描的数据量按查询计费,使其成为无需数据库基础设施的一次性分析的经济高效的解决方案。以下是一个示例查询:
-- Example: Token usage by model
SELECT
model_id,
SUM(input_tokens) as total_input_tokens,
SUM(output_tokens) as total_output_tokens,
COUNT(*) as conversation_count
FROM firehose_database.firehose_table
WHERE year='2025' AND month='08'
GROUP BY model_id
ORDER BY total_output_tokens DESC;此无服务器分析管道以最少的操作开销,将流经 AppSync 事件的数据转换为结构化、可查询的表。这些服务的按使用付费定价模式有助于成本效益,其托管特性减轻了基础设施预置和维护的需要。此外,由于您的数据已在 AWS Glue 中编目,您可以使用全套 AWS 分析和机器学习服务(如 Amazon Quick Sight 和 Amazon SageMaker Unified Studio)来处理您的数据。
监控
AppSync 事件和 Lambda 函数会将指标发送到 CloudWatch,以便您可以有效监控性能、排除故障并优化您的 AWS AppSync API 操作。对于 AI 网关,您可能需要在监控系统中获取更多信息,以跟踪重要的指标,例如模型的 token 消耗情况。
示例应用程序在每个对话轮次结束时包含一个对 CloudWatch 指标的调用,用于记录 token 消耗和 LLM 延迟,以便操作人员可以实时了解这些数据。这使得可以将指标包含在仪表板和警报中。此外,指标数据包含 LLM 模型标识符作为维度,因此您可以按模型跟踪 token 消耗和延迟。指标是我们使用 CloudWatch 了解应用程序运行时情况的诸多组成部分之一。因为我们的日志消息格式化为 JSON,所以我们可以使用 CloudWatch Logs Insights 对日志数据进行分析以进行监控。下图说明了 AppSync 事件和 Lambda 提供的日志和指标... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区